Sidans innehĺll:
Lexikon
Inledning
Lexikonstöd
Litteratur
Andra alfabet
Nya lexikon
Ordlistor
Ordbok
Om mellansprĺk
Interlingua
Kinesiska
Melodier
Matematik
Teckensprĺk
Stavning
Lära läsa
Tangentbord
Hämta
Lexikonstatus
Länkar
(Gamla pensionärsdalersidan)
Nytt
INLEDNING
=========
Jag har gjort ett program för att läsa och skriva med lexikonstöd.
Programmet heter LexSup. Tills vidare är det fritt tillgängligt och
kan laddas ner frĺn denna sida. När det kommit över sina barnsjukdommar
och när lexikonen växer sĺ att de inte längre ryms pĺ hemsidan planerar
jag att lĺta det ingĺ i en CD som jag säljer för 75:-.
En betaversion av hela LexSup finns t v pĺ denna hemsida. Klicka pĺ
LexSup
för att ladda ner denna. Den är pĺ c:a 5 MB.
JAG HAR NU LAGT IN LexSup MED BROWSER I INSTALLATIONSPROGRAMMET. OM DEN
INTE FUNGERAR FINNS DET GAMLA INSTALLATIONSPROGRAMMET UNDER RUBRIKEN
Lexikoncentral PĹ
http://hem2.passagen.se/lean2724
Om du vill prova LexSup utan att installera det kan du hämta enbart själva
programmet. Om du klickar pĺ nedanstĺende länk fĺr du ( om du inte har
nĺgot speciellt nedladdningsprogram) en dialogruta. Om du i den klickar
pĺ Öppna hämtas programmet till en tillfällig mapp och startas. Den
tillfälliga mappen töms när du rensar Temporary Internet Files. Det
som startar är själva programmet som kan köras utan att det är installerat
men det har inga lexikon med sig. Du fĺr själv hämta och lägga in lexikon.
LexSup-programmet
LEXIKONSTÖD
============
För att skriva och läsa med lexikonstöd behöver man
ett program som kan slĺ upp ord sĺ snabbt att det inte bryter
tankerytmen
bra lexikon som ger aktuella alternativ för alla ord
LexSup fungerar tillräckligt snabbt och utan att man behöver bryta
skrivrytmen eller läsrytmen. Men problemen att fĺ fram bra lexikon
visade sig vara större än väntat. Det mesta som finns är oĺtkomliga
filer som nĺgon försöker tjäna pengar pĺ. Vanligtvis är de knutna till
nĺgot program för att slĺ i dem med nĺgon metod som är helt orimligt
lĺngsam. Och för lite mer ovanliga sprĺk är det mycket svĺrt att hitta
nĺgot alls.
Lexikon är färskvara med ganska kort bäst-före-datum. Sprĺk förändras
hela tiden och modeord byts ut redan inom nĺgra fĺ ĺr. Det gäller
alltsĺ att fĺ fram lexikon som underhĺlls sĺ att de speglar aktuellt
sprĺkbruk.
LexSup skulle kunna användas som ett verktyg för invandrare och andra
flersprĺkiga personer som dĺ och dĺ behöver lexikonstöd för att läsa
eller skriva. LexSup använder lexikon som är öppna textfiler som vem
som helst kan ändra med vilken ordbehandlare som helst, t ex med
LexSup. Det är ocksĺ lätt att lägga in kompletteringar. Stöter man pĺ
nĺgot ord som inte finns i det lexikon man använder eller nĺgot ord
som bör förses med nĺgot mer översättningsalternativ är det lätt att
komplettera lexikonet. Pĺ det sättet kan man bygga upp ett allt mer
komplett eget lexikon.
I LexSup ingĺr även en möjlighet att lägga samman lexikon. Om du känner
nĺgon som du vet har byggt upp ett bra lexikon kan du lägga samman detta
lexikon med ditt eget. Du fĺr dĺ ett lexikon som innehĺller allt som
finns i nĺgot av dessa lexikon (fungerar f n endast för glosdelen, ej för
kommentardelen).
Möjligheten till lexikonaddition öppnar en möjlighet att utbyta lexikon
över Internet. Det som behövs är en Svensk Lexikoncentral som kan ta
emot och lägga ut lexikon. Nĺgon borde ta hand om denna uppgift men
tills vidare kan jag använda denna sida för detta. Har du ett lexikon
som du vill dela med dig av sĺ maila det till mig sĺ lägger jag ut det
här.
LITTERATUR
===========
När man vill stifta bekantskap med ett nytt sprĺk och en ny kultur är
ett problem att man behöver övningstexter som kan bidra med
sprĺkkänsla och känsla för kultur och tankesätt kring sprĺket.
Det mesta som finns pĺ svenska finns i form av pappersböcker. För att
kunna läsa dessa med hjälp av LexSup mĺste man scanna dem och bearbeta
de scannade sidorna med ett OCR-program som ger textfiler som kan
hämtas in i LexSup. Detta innebär ett visst besvär och för att
tillhandahĺlla lättare tillgängliga texter har jag lagt upp nĺgra
svenska texter som textfiler.
Det är nĺgra texter av äldre svenska författare där copyrighten löpt ut
sĺ att de kan läggas ut utan problem med utgivningsrättigheter och nĺgra
avsnitt av mina egna texter.
Texter 70 kB
2007-10-10 har jag tagit bort en klocka och visan om Kung Gustavs sardiner
ur Litteraturmappen för att fĺ plats med annat. Visan om V-gurras sardiner
finns att hämta pĺ min huvudsida.
Projekt Runeberg börjar nu fĺ en ganska omfattande katalog över äldre
svensk litteratur. Mycket är i form av textfiler som direkt kan kopieras
och läsas i LexSup. Projekt Runeberg finns pĺ
http://runeberg.org
Pĺ
http://stenhur.nu
finns länkar till korta texter som man kan använda som övningstexter (eller
bara läsa). Här är ett smakprov:
Det var en neger i Mo i Rana
som reste hem för att bo i Ghana
men dit kom han ej nĺnsin
han blev fast i Wisconsin
och gift med en mohikana
Fast ordet mohikana finns nog inte i nĺgot lexikon- - -.
ANDRA ALFABET
==============
När man försöker ĺstadkomma lexikon för olika sprĺk upptäcker man snart
att det finns mĺnga andra alfabet än och mĺnga varianter pĺ det latinska
alfabetet.
Ett stort sprĺk som ryska använder det kyrilliska alfabetet och för att
göra ett svensk-ryskt lexikon mĺste man alltsĺ använda sĺväl det svenska
som det kyrilliska alfabetet. Arabiska använder ocksĺ ett särskilt
alfabet och skiljer sig dessutom frĺn vĺrt vanliga skrivsätt genom
att man skriver baklänges och genom att bokstäver har olika form
beroende pĺ var i ett ord de stĺr.
I datateknikens barndom var minneskapaciteten mycket knapp och man
försökte använda sĺ fĺ bits som möjligt för att lagra texter. När
kostnaden för minnen sjönk började man alltmer acceptera principen
att använda en byte (8 bits) per tecken. Det ger 256 möjligheter per
tecken. Vissa asiatiska skrivtecken t ex kinesiska och japanska har
mer än 256 olika tecken men för mĺnga alfabet räcker 256 möjligheter
för att samtidigt ha det latinska alfabetet och ett annat alfabet.
Ett problem med främmande alfabet är ocksĺ att tangentbordets tangenter
inte räcker till för att adressera alla 256 möjligheter i en enbytesfont.
I LexSup finns möjligheter att styra tangentbordet till rätt tecken och
för arabisk skrift läggs tecknen in i omvänd ordning. Med LexSup
följer en kyrillisk font, en grekisk font och ett utkast till arabisk
font. Mina kunskaper i arabiska är emellertid inte tillräckliga för
att göra en korrekt arabisk font (tacksam för synpunkter pĺ detta!!).
NYA LEXIKON
===========
Pĺ hemsidan
http://web.telia.com/~u85724740
har Peter Bondesson ett lexikonprogram med nĺgra olika lexikon. Dessa
är skrivna i ett format som gör dem ĺtkomliga och jag tänker anpassa
dem för LexSup och lägga ihop dem med mina gamla lexikon. Jag har
börjat med svenska-latin och svenska-swahili.
Tills vidare är jag lite osäker pĺ om anpassningen fungerar sĺ jag
lägger inte in dessa lexikon i installationsprogrammet utan i en
särskild mapp som du kan hämta genom att klicka pĺ
nyalex.zip
I nyalex.zip finns även en omvändning av det svensk-latinska lexikonet
till ett latinskt-svenskt och i Ordlistor finns en latinsk-engelsk
ordlista.
Utbildningsdepartementet har pĺ sidan
http://www3.skolverket.se/ki/eng/sv_en_lexikon.pdf
en pdf-fil med en svensk-engelsk ordlista för omrĺdet forskning och
utbildning. Via Google kan man hämta den i html-format. Jag har gjort
det. Via Word har jag gjort om den till en textfil som jag har rättat
pĺ nĺgra punkter. Resultatet av detta finns i mappen ordlistor.zip.
Och frĺn denna har jag gjort ett LexSup-lexikon som ingĺr i nyalex.zip
(svenfu).
ORDLISTOR
=========
Pĺ hemsidan http://www.riksbank.se/templates/Page.aspx?id=20973 har
Riksbanken en ordlista som jag hämtat och gjort om till textfil.
Pĺ hemsidan
http://www.math.ubc.ca/people/faculty/cass/frivs/latin/latin-dict-full.html
har jag hittat en latinsk-engelsk ordlista som jag gjort om till textfil
och gjort nĺgra smĺändringar i.
Utbildningsdepartementet har pĺ sidan
http://www3.skolverket.se/ki/eng/sv_en_lexikon.pdf
en pdf-fil med en svensk-engelsk ordlista för omrĺdet forskning och
utbildning. Via Google kan man hämta den i html-format. Jag har gjort
det. Via Word har jag gjort om den till en textfil som jag har rättat
pĺ nĺgra punkter.
Jag har gjort en ordlista av Peter Bondessons svensk-engelska lexikon.
Den heter sven2klist.txt. Och frĺn hans svensk-norska lexikon har jag
gjort en ordlista som heter svno2klist.txt. Jag har även lagt hans
svensk-danska lexikon som en ordlista som heter svda2klist.txt och
hans svensk-polska svpo2klist.txt. Använd charset 238 (Options-Font)
och musskrift för att fĺ polska bokstäver. Hantering av charset är
knepig. I bruksanvisningen för musskrift finns beskrivet hur det gĺr
till i LexSup.
Jag har börjat göra ett utkast till en svensk-lettisk ordlista. Det är
förbluffande svĺrt att hitta nĺgot användbart om de baltiska sprĺken
men jag har hittills hittat 46 uppslagsord.
När det gäller holländska har WordGumbo en holländsk-engelsk ordlista
som gĺr at använda direkt i LexSup. Jag har lagt in den i zip-filen
med ordlistor.
För att kunna använda ordlistor med lĺng text för varje uppslagsord,
d v s den typ av lexikon som används för vanliga papperslexikon, har
jag lagt in en möjlighet att avsluta rader med # vilket betyder "Läs
och visa nästa rad". I konverteringsprogrammet finns en möjlighet att
lägga in # som radslut. Konverteringsprogrammet kan hämtas via Hämta
Dessa ordlistor finns i en zip-fil med ordlistor. Pĺ grund av platsbrist
pĺ den här sidan har jag flyttat den till
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ menyn).
Jag har ocksĺ hämtat början pĺ en svensk-latinsk ordbok frĺn Projekt
Runeberg. Mer om den finns pĺ http://hem2.passagen.se/lean2724
Pĺ
http://hem.passagen.se/eramura/svenska/ordindex.htm
har Mujde Rashid lagt en svensk-kurdisk ordlista. I mappen ordlistor.zip
som ligger under rubriken Lexikoncentral pĺ http://hem2.passagen.se/lean2724)
finns denna ordlista anpassad för att kunna användas som ordlista i
LexSup. I denna version av ordlistan är kurdiska ord skrivna med
latinska bokstäver.
ORDBOK
======
Även när jag skriver eller läser svenska texter händer det att jag stöter
pĺ ord som jag behöver slĺ upp. Det handlar dĺ inte om lexikon som ger
översättningsförslag utan om en ordbok som ger förklaring i form av en
synonym eller ett par förklarande meningar. Det händer sĺ sällan att det
inte är nĺgot stort problem att jag mĺste slĺ upp i en pappersbok men
ibland skulle jag vilja ha en ordbok som jag kan nĺ direkt via LexSup.
Inom projekt Runeberg ( http://runeberg.org ) finns en gammal ordbok som heter
"Främmande ord i svenska - Folkets uppslagsbok". Den är visserligen frĺn
1927 och en hel del är förĺldrat. Men en del är intressant och sĺdant som
kan vara mycket svĺrt att hitta i modernare verk. Jag har börjat anpassa den
för att passa till LexSup sĺ att den kan fungera som en stomme där man kan
lägga in nytt material.
Jag har gjort en första genomgĺng av den och rättat till en del formatfel o dyl men
i stort sett är den i det skick som den har inom projekt Runeberg. Jag har bara pĺ
nĺgra ställen rättat till innehĺllet. Det som är klart kan du hämta genom att
klicka pĺ
ordbok.zip
Hur du lägger in och använder ordboken finns beskrivet i Bruksanvisningar -
Ordlista under rubriken Begynnelsebokstavslistor.
Jag har gĺtt igenom lite mer av ordboken men den nya versionen ryms inte pĺ den
här sidan sĺ den ligger pĺ
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
UPPSLAGSLEXIKON
===============
Jag har gjort ett utkast till uppslagslexikon som finns att hämta under rubriken
Lexikon ovan
Detta är ett första utkast till ett uppslagslexikon. För att snabbt komma till nĺgot
användbart har jag utgĺtt frĺn den ovan nämnda gamla ordboken som heter "Främmande ord i
svenska sprĺket - Folkets uppslagsbok". Den är frĺn 1927 och finns i textformat inom
projekt Runeberg ( http://runeberg.org ) . Mycket i den är förĺldrat,
en del är lite tveksamt och det finns nog kvar en del inläsningsfel men jag har
bara i nĺgra enstaka fall rättat eller kompletterat. En del uppgifter, mest gamla
socialister, är sĺdant som är bortrensat och svĺrt att hitta i modernare verk.
Förutom den gamla ordboken innehĺller detta lexikon en mapp som heter web.
I den finns en fil med länkar som LexSup kombinerar med Inordet. Dessa
länkar visas i Utordrutorna och om du aktiverar (klickar pĺ) en sĺdan slĺs
den upp i Browserrutan.
Dessa länkar gĺr till Den Stora Svenska Ordboken och till Svenska Wikipedia.
Det är ännu glest med ordförklaringar i Den Stora Svenska Ordboken men för
mĺnga ord finns böjningsformer angivna.
OM MELLANSPRĹK
==============
Det är svĺrt att hitta bra lexikon mellan svenska och andra mindre sprĺk. Om
man kunde använda t ex engelska som mellansprĺk, d v s använda ett lexikon till
engelska plus ett lexikon frĺn engelska till svenska, skulle man kunna komma ĺt
mĺnga fler sprĺk.
Vĺra ord är symboler för avgränsade delar av verkligheten. Dessa avgänsningar ligger
olika i olika sprĺk och det finns därför sällan en entydig översättning av ett ord.
Om man försöker översätta ett ord frĺn ett sprĺk till ett annat och därifrĺn till ett
tredje är risken stor att man hamnar helt fel. Men om man använder metoden med stor
försiktighet kan den ändĺ ibland vara användbar.
Ĺteruppslagsmöjligheten i LexSup gör det möjligt att använda tvĺstegsuppslagning.
Antag att man har ett tysk-engelskt lexikon och ett engelsk-svenskt. Om man dĺ vill
läsa en text pĺ tyska kan man lägga det tysk-engelska som Lexikon2 och det engelsk-
svenska som Lexikon1. Om man dĺ dubbelklickar pĺ ett ord i en tysk text fĺr man
översättningsförslag pĺ engelska frĺn det tysk-engelska lexikonet. Av dessa kan man
genom att skriva 1 , 2 eller 3 välja ett som dĺ slĺs upp i det engelsk-svenska
lexikonet och ger översättningsförslag till svenska.
För att göra det möjligt att prova detta har jag lagt ut ett lexikon mellan tyska
och engelska. Det ryms emellertid inte pĺ den här hemsidan men det gĺr att hämta
via
http://hem2.passagen.se/lean2724
(Av nĺgon anledning fungerar inte en direktlänk sĺ ovanstĺende länk gĺr till
öppningssidan där man fĺr klicka pĺ "Lexikoncentral" pĺ menyn)
Där finns ocksĺ ett konverteringsprogram som gör om en del ordlistor till
insorteringslistor för LexSup. Och där finns engelsk-isländskt och engelsk-polskt
lexikon gjorda frĺn WordGumbos ordlistor. Konverteringsprogrammet kan även
hämtas via Hämta
INTERLINGUA
============
De flesta europeiska sprĺk har lĺnat en mängd ord frĺn latinet, ofta som
synonymer till andra ord. Det gör att man kan skapa ett sprĺk av vanliga
latinska ord som en läsare kan, ĺtminstone delvis, begripa redan vid
första kontakten med sprĺket. Ett sĺdant sprĺk är Interlingua.
Det finns hundratals sprĺk i världen. Om man skall göra lexikon mellan alla
dessa krävs ett stort antal olika lexikon. En enklare lösning är dĺ att för
varje sprĺk göra ett lexikon till och ett lexikon frĺn ett gemensamt
mellansprĺk, till exempel Interlingua. Med tvĺstegsuppslag kan man dĺ i LexSup
slĺ upp ord mellan sprĺken.
Översättning är ett ord med mĺnga bottnar. För att förstĺ en dikt av Fröding
räcker det inte med att kunna svenska, man mĺste kunna värmlänska och inte
nog med det, man mĺste ha vuxit upp i södra Värmland. Sĺ hur översätter man
en sĺdan dikt? Men i mĺnga fall handlar det inte om att förstĺ en text, bara
om att begripa vad den handlar om. Och det är betydligt enklare. Sĺ enkelt
att tvĺstegsuppslag kan vara användbart.
Tvĺstegsuppslag är en värdelös metod för en grek som vill läsa Dan Andersson.
Men det kan vara en användbar metod för en ryss som vill veta vad svensk lag
säger om en viss trafikförseelse.
Som ett första steg pĺ vägen mot lexikon till och frĺn Interlingua har jag gjort
ett LexSup-lexikon (Interlingua) frĺn en ordlista som jag hämtat pĺ hemsidan för
Svenska Sällskapet för Interlingua
http://www.interlingua.nu
Frĺn Jan Ĺrmann har jag fĺtt nĺgra större ordlistor anpassade för programmet
Vokabel. Vokabel finns pĺ
http://www.pekspro.com
Frĺn dessa har jag gjort LexSup-lexikon mellan Interlingua och svenska,
engelska, italienska, norska och danska. Man kan, med dessa ordlistor, slĺ upp
t ex frĺn svenska till italienska genom tvĺstegsuppslag med Interlingua som
mellansprĺk. Dessa lexikon ligger i en zip-fil pĺ c:a 2 MB. Den ryms inte pĺ
denna sida sĺ länken till den är en direktlänk till en sida där jag fortfarande
hade lite plats kvar.
Interlingua2
KINESISKA
=========
I Unicode ingĺr c:a 40 000 kinesiska skrivtecken. Du kan skriva kinesiska
tecken med Charset 134. Om du gĺr in pĺ Options - Font och sätter Charset
till 134 och därefter aktiverar Musskrift kan du med musskrift skriva
kinesiska tecken (fungerar under WindowsXP kanske ej under Windows98). Tvĺ
musskrifttecken ger ett kinesiskt tecken. Det finns ocksĺ i det kinesiska lexikonet
nĺgra enstaka ord skrivna med Charset 136. Detta Charset används pĺ samma
sätt som Charset 134.
De finns även en annan möjlighet att skriva kinesiska tecken. Om du har
satt Charset till 134 men inte aktiverat Musskrift visas den vanliga utfilrutan.
I denna kan du skriva med tangentbordet och om du klickar pĺ
Options - Främmande latinskt till special fĺr du via tangentbordsförskjutning
möjlighet att skriva tecken i övre delen av byten. Du kan dĺ skriva teckenpar
som tolkas som kinesiska tecken om du aktiverar Musskrift.
När du väljer Charset mellan 128 och 138 sätts LexSup i Kinesmod. Det betyder att
bland annat uppslag i lexikon fungerar lite annorlunda. Normalt sker uppslag efter
begynnelsebokstav och inom varje begynnelsebokstav med början frĺn andra
bokstaven. Pĺ det viset kommer man ifrĺn problemet med att ord kan ha stor eller
liten bokstav som första bokstav. I kinesiska lexikon blandas emellertid flera tecken
med olika inledande byte i samma fil och sorteringen görs därför frĺn första bokstav
även inom varje lexikonfil. Det är därför ibland viktigt att veta om LexSup är i
Kinesmod eller inte. För att visa detta övergĺr Inordrutans färg till fuchsia när LexSup
befinner sig i Kinesmod.
I LexSup gĺr det alltsĺ att skriva pĺ kinesiska men det är ju ganska meningslöst
om man inte vet vad skriften betyder. Jag har ännu inte hittat nĺgot bra sätt
att göra lexikon och slĺ upp kinesiska tecken. Men en bra första introduktion
till vad tecknen betyder finns pĺ
http://http://www.zein.se/patrick/chinsv3p.html
Där finns c:a 75 kinesiska tecken. De lĺter som en droppe i havet men det finns
en viss ordning pĺ tecknen som man kan ana när man tittar närmare pĺ dem och det
lär räcka med att man kan c:a 500 för att man skall kunna läsa ganska bra.
Pĺ bokrean 2007 sĺldes ocksĺ en bok av Cecilia Lindqvist, Tecknens Rike, där man
kan läsa om hur tecknen vuxit fram.
I html-text kan man lägga in kinesiska tecken med &# följt av en siffra mellan
20000 och 60000.
Du kan göra ett svensk-kinesiskt lexikon genom att under uppslagsorden lägga in
HTML-unicode för motsvarande tecken. När du dĺ slĺr upp med dubbelkomma och
väljer ett tecken visas koden i Utfilrutan och om du har en Browserruta knuten
till Utfilrutan kan du i den se hur tecknet ser ut. Ett alternativ till ett sĺdant
lexikon är att använda frasmod (se Tangentbord nedan). Men antalet kinesiska tecken
är för stort för att man skall kunna adressera alla tecken med en tangenttrryckning.
I frasmod2 kan man emellertid använda längre adresser och du kan alltsĺ i OrdFras2.tab
lägga in kinesiska tecken som du döper till namn som du finner lämpliga. I installations-
programmet ingĺr en OrdFras2.tab där jag har försökt visar hur man kan göra men
jag kan för lite kinesiska för att kunna hitta tecknen. Jag är inte ens säker pĺ
att de fĺ jag tagit är rätt.
För att ha nĺgon nytta av ett kinesiskt lexikon mĺste man ha nĺgon anledning att
skriva eller läsa pĺ kinesiska. Man behöver lämpliga texter pĺ kinesiska. Pĺ
http://www.gutenberg.org
finns mer 50 böcker pĺ kinesiska. Men de är kodade med UTF8-kod. Lexikonen i
LexSup fungerar inte med UTF8-kod och man kan inte spara en UTF8-kodad i
Utfilruta utan att all UTF8-kod förstörs. Men man kan göra om UTF8 till
tvĺbytes unicode. Om det är en fil med UTF-8-märke (inledande bytes 239 187 191)
eller om strängen UTF-8 ingĺr i de inledande 2000-tecknen fĺr du upp en ruta
som ger dig möjlighet att konvertera filen. Om du hämtar med "Hämta filtrerad fil"
fĺr du alltid möjlighet att konvertera filen.
En annan möjlighet är att man väljer en bok i Projekt Gutenbergs katalog och
scrollar ner till nerkanten av sidan där det finns en länk som heter
"online recoding service". Klickar man pĺ den fĺr man möjlighet att välja
target code där ett av alternativen heter UCS-2. Man fĺr dĺ filen kodad i
tvĺbytestecken med byten omkastade sĺ att minst signifikant byte ligger först.
För tecken i första byten blir dĺ andra bytens värde noll. Men Utfilrutan i
LexSup kan inte ta emot bytes med värdet noll. Det tolkas som att inladdningen
skall stoppa. Använd därför "Hämta filtrerad fil" under "Arkiv". Klicka pĺ det
och välj "Omvänd tvĺ-byteskodning (UCS-2)" sĺ laddas filen in med unicode
för html-text. Sparar du den som en htm-fil kan du ta fram browserrutan med
"Internet" pĺ huvudmenyn och se de kinesiska tecknen. Och du kan slĺ upp i
lexikonet pĺ vanligt sätt.
Lite mer om att skriva och läsa pĺ kinesiska finns i kinesbrev.htm.
Kinesiska tecken är uppbyggda av c:a 30 olika kaligrafistreck. Pĺ samma sätt som vi
kombinerar bokstäver till ord kombinerar man kaligrafistreck till tecken. Om man knyter
tangentbordets tangenter till kaligrafistreck kan man alltsĺ skriva kinesiska tecken pĺ
liknande sätt som vi skriver vĺra ord. Det mĺste finnas en väl etablerad standard för vilka
steck som skall knytas till vilka tangenter. Jag har ännu inte hittat hur denna standard ser ut
och jag avvaktar därför med att lägga in ett sĺdant tangentbord. För att visa principen finns
emellertid under "Options -Tangentbord - Kaligrafistreck" en möjlighet att skriva nĺgra
enstaka streck som ligger knutna till tangenterna Q A Z q a z R U b c.
MELODIER
========
Med Spelled speech kan man i princip spela melodier. Vid Spelled speech aktiverar
varje tecken eller teckengrupp (max 6 tecken) en ljudfil som, om inget annat
angetts, ligger i mappen Spsp. För att fĺ nĺgot som liknar tal lägger man ljudfiler
som motsvarar bokstävernas ljudvärde men det är naturligtvis inget som hindrar att
man i stället lägger ljudfiler som ger olika toner. För att visa den här
möjligheten har jag lagt in ljudfiler som motsvarar siffertecken och för dessa har
jag lagt in toner. Om du skriver 1 och kör Spelled speech (p g av en bug i
programmet läser inte AUTO slutet av texten sĺ se till att lägga in lite text efter
ocksĺ) kommer du att höra en kvartston motsvarande C, skriver du 2 fĺr du D o s v
upp till 8 som är C i nästa oktav. Skriver du 102 fĺr du i stället en
ĺttondelston av C. Jag har bara lagt in kvarts och ĺttondelstoner men det är ju
lätt att lägga in fler toner.
Pĺ
http://www.threechords.com/hammerhead/cool_edit_96.shtml
kan du ladda ner ett program som heter Cool_Edit. Gratisversionen är ett shareware-
program där man inte samtidigt kan ha alla funktioner tillgängliga men det fungerar
helt OK för att göra toner i form av .wav-filer.
Prova att skriva 1113222433221 i Utfilrutan och aktivera Spelled speech eller
kopiera in det direkt i Editrutan i Spelled speech - panelen. Eller prova
11202334554023 3223432131 .
I panelen för Spelled speech har jag lagt till en knapp som heter Ljud som gör att
man kan fĺ upp en dialog där man kan välja ljudbibliotek om man vill skapa ett sĺdant
i nĺgon annan mapp än Spsp. Jag har ocksĺ lagt till en knapp som heter Igen och som
repeterar det som stĺr i Editrutan.
Jag har kompletterat Spsp med nĺgra toner. För att fĺ med toner ur nästa oktav har
jag döpt dem till 1a (som är samma som 8), 2a , 3a och 4a. Som exempel finns här
melodin till "Sĺ lunka vi"
144668 6s02 6544566s 6025144668 6s026544334 144668 6s02 6544566s 6025144668 6s026544334 8028026s553a4a88802 8026s553a4a88802 8026s6s02 6s026602 6025502 502445026026s025024023022023024
Markera den, kopiera med ctrl-C och klistra in den i Editrutan i Spelled speech.
Pĺ
http://www.tucows.com/preview/193454
finns ett freeware-program som heter Anvil-Studio. Med det kan man ĺstadkomma toner,
ackord, melodier mm. Även om det kan göra en del med .wav-filer är det huvudsakligen
avsett för midi-filer. Jag har därför i LexSup lagt in en möjlighet att även använda
midi-filer med filtillägget .mid. Hur man gör finns beskrivet i bruksanvisningen för
Spelled speech.
Som exempel pĺ användning av detta har jag i installationsprogrammet lagt med en
mapp som heter Lunka. Den finns alltsĺ i den mapp där du installerar LexSup. Hämta
filen lunka.trs i denna mapp.
MATEMATIK
=========
Matematik är ett sprĺk som används frĺn specerihandlarens prosa till poesin i
Gödels ofullständighetssats. Men mĺnga av matematikens begrepp använder vi sĺ
sällan att vi ibland behöver slĺ upp dem för att se hur de avgränsas pĺ vanligt
vardagssprĺk.
Pĺ hemsidan
http://matmin.kevius.com/index.html
har Bruno Kevius lagt en matematisk uppslagsbok. Jag har av hans innehĺllsförteckning
gjort ett lexikon som kan läggas in i LexSup. Detta slĺr upp länkar till hans
uppslagsbok. När man aktiverar (klickar pĺ) en sĺdan länk slĺs den upp via
Internet och visas i LexSups browser. För att ĺtergĺ till Utfilrutan stänger man
browsern.
Hämta lexikonet genom att klicka pĺ
matematik.zip
TECKENSPRĹK
===========
Det är mycket lätt att i LexSup lägga in bilder som visar teckensprĺkssymboler.
Om man t ex i ett lexikon vill lägga in en bild som visar hur ordet "bĺt" ser
ut pĺ teckensprĺk lägger man i det lexikonet in en mapp som heter bild och i den
lägger man en bildfil som heter bĺt.bmp eller bĺt.jpg. När man dĺ slĺr upp ordet
bĺt visas denna bild. Det gĺr även att lägga in bildsekvenser pĺ upp till tio
bilder för att visa rörelser.
För att visar hur detta fungerar har jag i det svensk-engelska lexikonet (sven)
lagt i teckensprĺksbilder för bĺt och bil.
Det finns nĺgra problem med detta. Ett är att jag inte vet om det fungerar när
man kommer upp i tusentals ord. Möjligheten att visa bilder var egentligen tänkt
för enstaka bilder. Ett annat är att varje bild tar nĺgot tiotal kB vilket medför
att det inte gĺr att fĺ plats med ett teckensprĺkslexikon pĺ min hemsida.
STAVNING
========
OBS! Stavningskontrollen i LexSup fungerar inte under Windows 98!
Jag har länge tänkt lägga in nĺgon form av stavningskontroll i LexSup. Jag
provade med ett färdigt stavningsprogram men resultatet blev att det inte
gick att starta LexSup om man inte köpt en krypterad ordlista.
Men nu finns nĺgra användbara ordlistor. Lars Aronsson har inom Projekt
Runeberg (se LÄNKAR) en ordlista och pĺ i Kurts hurts (se under LÄNKAR)
finns denna med ett hanteringsprogram som kan sortera ord bĺde frĺn början
och slutet. Med hjälp av detta sorteringsprogram har jag gjort en ordlista som
är anpassad för LexSup och denna har jag lagt in i installationsprogrammet.
Med hjälp av Kurts ordlistor och script har jag även anpassat en engelsk
stavningsordlista för LexSup. Den finns att hämta under rubriken LEXIKON
ovan.
LÄRA LÄSA
=========
En person som lär sig läsa kan ha ett visst stöd av Spelled speech. För att barn
skall kunna börja använda Spelled speech krävs en viss anpassning som ger
enkel hantering av enkla övningstexter. Under Spelled speech finns nu en möjlighet
att läsa övningstexter i Lära-läsa-mod.
Tyvärr är fortfarande bokstavsljuden i mappen Spsp mycket dĺliga. Du kan
säkerligen ĺstadkomma bättre med hjälp av den Ljudinspelare som ingĺr i
Windows.
Som exempel pĺ övningstext har jag frĺn Kurts hurts (se LÄNKAR) hämtat
början pĺ Ivar Arosenius Kattresan. Men ljudfiler är skrymmande och trots
att jag bara lagt in nĺgra fĺ sĺdana ryms den inte pĺ denna sida. Den ligger
i stället under rubriken Lexikoncentral pĺ
http://hem2.passagen.se/lean2724
Passagens hemsidor fugerar inte längre.
Använd i stället direktlänken nedan
Kattresan
Hur fort bör man läsa? För att fĺ flyt i Spelled speech och för att fĺ plats med
alla ljud pĺ hemsidan har jag använt bokstavsljud med en längd av c:a 0,1 sekund.
När man övar läsning kan man behöva längre bokstavsljud för att kunna uppfatta
övergĺngen mellan ord-ljud och en serie bokstavsljud. Det finns därför en möjlighet
att i Lära-läsa-mod snabbt växla mellan olika mappar med bokstavsljud. Dessa
mappar skall heta Spsp, Spsp1, Spsp2 osv och de mĺste ligga i samma mapp.
Genom att jag börjat lägga filer pĺ min Ekonomisida har jag fĺtt lite mer utrymme
och jag har därför lagt en mapp som heter Spsp1 där jag bytt ut en del bokstavsljud
mot sĺdana som är c:a 0,3 sekunder. Jag där ocksĺ tagit bort toner för att skriva
melodier eftersom detta knappast är aktuellt vid läsövning.
Du kan hämta denna mapp via direktlänken:
 Spsp1 Lĺngsamma bokstavsljud till Lära läsa
I LexSup kan den som vill enkelt skapa egna toner, bokstavsljud, stavelseljud, ordljud
och meningsljud. Genom att skriva samman dessa kan man sĺ uppleva hur toner flyter
samman till melodier och bokstavsljud flyter samman till ord. Det ger en möjlighet
att lära sig läsa pĺ ett helt nytt sätt. Men hur denna möjlighet skall användas i en
värld där en dator är pĺ väg att bli ett lika självklart skolhjälpmedel som forna tiders
pennskrin, det är en frĺga som jag inte har möjlighet att bearbeta.
TANGENTBORD
=============
Hur skriver man ett sprĺk med annat alfabet om man samtidigt vill kunna slĺ upp svenska
ord? Jag har provat att använda tangentbordsförskjutning och musskrift för detta men det som
hittills fungerat bäst är att lägga in en möjlighet att skifta teckenuppsättning via Options -
Tangentbord.
Det finns nu en möjlighet att välja grekiska tecken eller rysk ASDF-uppsättning.
Det finns ocksĺ en möjlighet att göra en egen tangentbordsuppsättning. För att visa hur det
fungerar har jag lagt med filerna teck.tab och tangentbord.bmp som gör att alternativet Eget i
tangentbordslistan ställer om teckenplaceringen och visar en tangentbordsbild. Genom att
ändra i dessa filer kan du ändra teckenplaceringen.
Om man skriver text där vissa ord, fraser eller teckenkoder förekommer ofta kan det vara
praktiskt att kunna skriva dessa med ett fĺtal tangenttryckningar. Det finns nu (2008-04-11)
en möjlighet att sätta tangentbordet i frasmod. Hĺll nere Alt, tryck < och släpp. Tangnetbordet
är nu satt i frasmod. Nästa tecken medför att LexSup letar i en fil som heter OrdFras.tab
efter en rad som börjar med tecknet. Finns en sĺdan rad skrivs den in vid cursorn i Utfilrutan
fr o m tecken nr 3. Därefter skrivs ett mellanslag och tangentbordet ĺterställs till normal mod.
I OrdFras.tab kan du lägga in vilka ord, fraser eller teckenkoder du vill. För att visa hur det
fungerar ligger en OrdFras.tab med i installationsprogrammet. Där finns nĺgra HTML-unicoder
som kan vara bra att ha om man skriver html-text.
Trycker du Alt,> (alltsĺ Alt,Shift,<) visas OrdFras.tab i en smal ruta längs skärmens högra kant.
Den försvinner om du klickar pĺ den.
I frasmod kan du anropa en rad med ett tecken. Men om du vill anropa ett längre textavsnitt
eller använda fler adresser än det finns tecken pĺ tangentbordet räcker inte frasmod till. Det
finns dĺ en möjlighet att använda frasmod2. Hĺll nere Alttangeneten och tryck pĺ . . När du
släpper tangenterna sätts tangentbordet i frasmod2 vilket innebär att det kommer upp en gul
editruta i nedre vänstra hörnet pĺ Kommentarrutan. Skriv ditt uppslagsord där och avsluta med
ENTER. LexSup letar dĺ i den mapp där LexSup öppnades efter en fil som heter OrdFras2.tab.
Finns det en sĺdan letar LexSup efter en rad som börjar med . följd av uppslagsordet. Om det
finns en sĺdan rad lägger LexSup vid cursorn i Utfilrutan in följande rader fram till nästa rad som
börjar med . eller till slutet pĺ filen. Se även Kinesiska ovan.
Om man vill skriva ett längre avsnitt med tangentbordet i frasmod blir det jobbigt attt för varje
tecken aktivera frasmod. Man kan dĺ sätta tangentbordet i permanent frasmod. Det gör man
genom att i frasmod eller frasmod2 skriva : (i frasmod2 skall det vara första tecknet).
Tangentbordet sätts dĺ i permanent frasmod vilket man ser pĺ att det dyker upp en röd
stapel till höger om kommentarrutan. När man i permanent frasmod trycker pĺ Alttangenten
ĺtergĺr tangentbordet till engĺngs-frasmod.
HÄMTA
======
Välj vad du vill hämta genom att klicka pĺ nĺgon av följande rader:
LexSup 5 MB
FontMap 0,5 MB
Konverteringsprogram 0,22 MB (direktlänk)
Texter 2,3 MB
Fonter (Borttagen. Dessa fonter finns med i installationsprogrammet.)
Nya lexikon
Ordlistor (Finns nu pĺ http://hem2.passagen.se/lean2724)
Demo (ligger pĺ grund av platsbrist pĺ min huvudsida) (direktlänk)
Spsp1 Lĺngsamma bokstavsljud till Lära läsa (direktlänk)
JAG HAR NU LAGT IN LexSup MED BROWSER I INSTALLATIONSPROGRAMMET. OM DEN
INTE FUNGERAR FINNS DET GAMLA INSTALLATIONSPROGRAMMET UNDER RUBRIKEN
Lexikoncentral PĹ
http://hem2.passagen.se/lean2724
Om du vill prova LexSup utan att installera det kan du hämta enbart själva
programmet. Om du klickar pĺ nedanstĺende länk fĺr du ( om du inte har
nĺgot speciellt nedladdningsprogram) en dialogruta. Om du i den klickar
pĺ Öppna hämtas programmet till en tillfällig mapp och startas. Den
tillfälliga mappen töms när du rensar Temporary Internet Files. Det
som startar är själva programmet som kan köras utan att det är installerat
men det har inga lexikon med sig. Du fĺr själv hämta och lägga in lexikon.
LexSup-programmet
LEXIKONSTATUS
===============
följande lexikon hade 2009-03-29 följande omfattning:
Antal ord i gloslexikon
Uppslagsord Uppslagna ord
Svensk-engelsk 30 000 44 000
Svensk-finsk 24 000 32 000
Svensk-tysk 7 600 8 800
Svensk-spansk 26 000 28 000
Svensk-rysk 8 000 17 700
Svensk-fransk 3 800 3 900
Svensk-dansk 11 000 14 000
Svensk-polsk 400 450
Svensk-swahili 7 700 11 300
Kinesisk-svensk 5 000 5 000
Svensk-kurdisk 2 700 4 100
Svenska-Interlingua 27 000 48 000
LÄNKAR
======
Pĺ
http://stenhur.nu
finns länkar till korta texter som man kan använda som övningstexter (eller
bara läsa).
Pĺ
http://www.gutenberg.org
finns texter pĺ olika sprĺk som kan användas som övningstexter.
Pĺ
http://www.google.se/translate
finns Googles översättningsservice. Som vanligt ger deras maskinöversättning
ett praktiskt taget obegripligt resultat men där finns ocksĺ intressanta
ordböcker.
Hemsidan för Svenska Sällskapet för Interlingua finns pĺ
http://www.interlingua.nu
Peter Bondessons lexikonprogram med ett flertal lexikon finns pĺ
http://web.telia.com/~u85724740
Det krävs en viss bearbetning för att dessa lexikon skall gĺ att
använda i LexSup. De använder nollor som strängslut och kan alltsĺ hämtas in i
LexSup som filtrerade filer. Jag har använt en del av dem för att komplettera
lexikon och LexSup-ordlistor.
Pĺ
http://www.wordgumbo.com/index.htm
finns ett stort antal ordlistor mellan engelska och olika sprĺk. Dessa
ordlistor gĺr, i de flesta fall, att använda direkt som ordlistor i
LexSup. I Ordlistor har jag lagt in nĺgra av dessa listor (mappen Ordlistor
ligger nu pĺ
http://hem2.passagen.se/lean2724 .
Ett flertal texter som kan användas som övningstexter finns pĺ
http://runeberg.org
Det är texter av äldre författare där copyrighten gĺtt ut sĺ att texterna
kan användas fritt. I mĺnga fall finns dessa i textformat sĺ att de direkt
kan läsas med LexSup.
Pĺ
http://www.nordlund.lu.se/Fornsvenska/Fsv%20Folder/
finns nĺgra exempel pĺ texter pĺ gammal svenska och pĺ
http://spraakbanken.gu.se/fsvldb/
finns en möjlighet att fĺ förklaring pĺ ett ord i taget.
Pĺ Grimners runor
Spsp1 Lĺngsamma bokstavsljud till Lära läsa
I LexSup kan den som vill enkelt skapa egna toner, bokstavsljud, stavelseljud, ordljud
och meningsljud. Genom att skriva samman dessa kan man sĺ uppleva hur toner flyter
samman till melodier och bokstavsljud flyter samman till ord. Det ger en möjlighet
att lära sig läsa pĺ ett helt nytt sätt. Men hur denna möjlighet skall användas i en
värld där en dator är pĺ väg att bli ett lika självklart skolhjälpmedel som forna tiders
pennskrin, det är en frĺga som jag inte har möjlighet att bearbeta.
TANGENTBORD
=============
Hur skriver man ett sprĺk med annat alfabet om man samtidigt vill kunna slĺ upp svenska
ord? Jag har provat att använda tangentbordsförskjutning och musskrift för detta men det som
hittills fungerat bäst är att lägga in en möjlighet att skifta teckenuppsättning via Options -
Tangentbord.
Det finns nu en möjlighet att välja grekiska tecken eller rysk ASDF-uppsättning.
Det finns ocksĺ en möjlighet att göra en egen tangentbordsuppsättning. För att visa hur det
fungerar har jag lagt med filerna teck.tab och tangentbord.bmp som gör att alternativet Eget i
tangentbordslistan ställer om teckenplaceringen och visar en tangentbordsbild. Genom att
ändra i dessa filer kan du ändra teckenplaceringen.
Om man skriver text där vissa ord, fraser eller teckenkoder förekommer ofta kan det vara
praktiskt att kunna skriva dessa med ett fĺtal tangenttryckningar. Det finns nu (2008-04-11)
en möjlighet att sätta tangentbordet i frasmod. Hĺll nere Alt, tryck < och släpp. Tangnetbordet
är nu satt i frasmod. Nästa tecken medför att LexSup letar i en fil som heter OrdFras.tab
efter en rad som börjar med tecknet. Finns en sĺdan rad skrivs den in vid cursorn i Utfilrutan
fr o m tecken nr 3. Därefter skrivs ett mellanslag och tangentbordet ĺterställs till normal mod.
I OrdFras.tab kan du lägga in vilka ord, fraser eller teckenkoder du vill. För att visa hur det
fungerar ligger en OrdFras.tab med i installationsprogrammet. Där finns nĺgra HTML-unicoder
som kan vara bra att ha om man skriver html-text.
Trycker du Alt,> (alltsĺ Alt,Shift,<) visas OrdFras.tab i en smal ruta längs skärmens högra kant.
Den försvinner om du klickar pĺ den.
I frasmod kan du anropa en rad med ett tecken. Men om du vill anropa ett längre textavsnitt
eller använda fler adresser än det finns tecken pĺ tangentbordet räcker inte frasmod till. Det
finns dĺ en möjlighet att använda frasmod2. Hĺll nere Alttangeneten och tryck pĺ . . När du
släpper tangenterna sätts tangentbordet i frasmod2 vilket innebär att det kommer upp en gul
editruta i nedre vänstra hörnet pĺ Kommentarrutan. Skriv ditt uppslagsord där och avsluta med
ENTER. LexSup letar dĺ i den mapp där LexSup öppnades efter en fil som heter OrdFras2.tab.
Finns det en sĺdan letar LexSup efter en rad som börjar med . följd av uppslagsordet. Om det
finns en sĺdan rad lägger LexSup vid cursorn i Utfilrutan in följande rader fram till nästa rad som
börjar med . eller till slutet pĺ filen. Se även Kinesiska ovan.
Om man vill skriva ett längre avsnitt med tangentbordet i frasmod blir det jobbigt attt för varje
tecken aktivera frasmod. Man kan dĺ sätta tangentbordet i permanent frasmod. Det gör man
genom att i frasmod eller frasmod2 skriva : (i frasmod2 skall det vara första tecknet).
Tangentbordet sätts dĺ i permanent frasmod vilket man ser pĺ att det dyker upp en röd
stapel till höger om kommentarrutan. När man i permanent frasmod trycker pĺ Alttangenten
ĺtergĺr tangentbordet till engĺngs-frasmod.
HÄMTA
======
Välj vad du vill hämta genom att klicka pĺ nĺgon av följande rader:
LexSup 5 MB
FontMap 0,5 MB
Konverteringsprogram 0,22 MB (direktlänk)
Texter 2,3 MB
Fonter (Borttagen. Dessa fonter finns med i installationsprogrammet.)
Nya lexikon
Ordlistor (Finns nu pĺ http://hem2.passagen.se/lean2724)
Demo (ligger pĺ grund av platsbrist pĺ min huvudsida) (direktlänk)
Spsp1 Lĺngsamma bokstavsljud till Lära läsa (direktlänk)
JAG HAR NU LAGT IN LexSup MED BROWSER I INSTALLATIONSPROGRAMMET. OM DEN
INTE FUNGERAR FINNS DET GAMLA INSTALLATIONSPROGRAMMET UNDER RUBRIKEN
Lexikoncentral PĹ
http://hem2.passagen.se/lean2724
Om du vill prova LexSup utan att installera det kan du hämta enbart själva
programmet. Om du klickar pĺ nedanstĺende länk fĺr du ( om du inte har
nĺgot speciellt nedladdningsprogram) en dialogruta. Om du i den klickar
pĺ Öppna hämtas programmet till en tillfällig mapp och startas. Den
tillfälliga mappen töms när du rensar Temporary Internet Files. Det
som startar är själva programmet som kan köras utan att det är installerat
men det har inga lexikon med sig. Du fĺr själv hämta och lägga in lexikon.
LexSup-programmet
LEXIKONSTATUS
===============
följande lexikon hade 2009-03-29 följande omfattning:
Antal ord i gloslexikon
Uppslagsord Uppslagna ord
Svensk-engelsk 30 000 44 000
Svensk-finsk 24 000 32 000
Svensk-tysk 7 600 8 800
Svensk-spansk 26 000 28 000
Svensk-rysk 8 000 17 700
Svensk-fransk 3 800 3 900
Svensk-dansk 11 000 14 000
Svensk-polsk 400 450
Svensk-swahili 7 700 11 300
Kinesisk-svensk 5 000 5 000
Svensk-kurdisk 2 700 4 100
Svenska-Interlingua 27 000 48 000
LÄNKAR
======
Pĺ
http://stenhur.nu
finns länkar till korta texter som man kan använda som övningstexter (eller
bara läsa).
Pĺ
http://www.gutenberg.org
finns texter pĺ olika sprĺk som kan användas som övningstexter.
Pĺ
http://www.google.se/translate
finns Googles översättningsservice. Som vanligt ger deras maskinöversättning
ett praktiskt taget obegripligt resultat men där finns ocksĺ intressanta
ordböcker.
Hemsidan för Svenska Sällskapet för Interlingua finns pĺ
http://www.interlingua.nu
Peter Bondessons lexikonprogram med ett flertal lexikon finns pĺ
http://web.telia.com/~u85724740
Det krävs en viss bearbetning för att dessa lexikon skall gĺ att
använda i LexSup. De använder nollor som strängslut och kan alltsĺ hämtas in i
LexSup som filtrerade filer. Jag har använt en del av dem för att komplettera
lexikon och LexSup-ordlistor.
Pĺ
http://www.wordgumbo.com/index.htm
finns ett stort antal ordlistor mellan engelska och olika sprĺk. Dessa
ordlistor gĺr, i de flesta fall, att använda direkt som ordlistor i
LexSup. I Ordlistor har jag lagt in nĺgra av dessa listor (mappen Ordlistor
ligger nu pĺ
http://hem2.passagen.se/lean2724 .
Ett flertal texter som kan användas som övningstexter finns pĺ
http://runeberg.org
Det är texter av äldre författare där copyrighten gĺtt ut sĺ att texterna
kan användas fritt. I mĺnga fall finns dessa i textformat sĺ att de direkt
kan läsas med LexSup.
Pĺ
http://www.nordlund.lu.se/Fornsvenska/Fsv%20Folder/
finns nĺgra exempel pĺ texter pĺ gammal svenska och pĺ
http://spraakbanken.gu.se/fsvldb/
finns en möjlighet att fĺ förklaring pĺ ett ord i taget.
Pĺ Grimners runor
 finns bland mycket annat en beskrivning av varje runas innebörd.
När det gäller stungna kortkvistrunor har jag följt Kalle
Runristares anvisningar för moderna runstenar som jag hämtade
pĺ hans hemsida
http://www.runristare.se
Sedan dess har han ändrat hemsidan men det jag dĺ hittade har jag
använt för att göra fonten LexSupRun1 som installeras via LexSups
installationsprogram. Runorna ligger pĺ tangentbordets versaler,
alltsĺ med shift. Använd Caps Lock och "Option - Främmande Latinskt
till Special" för att skriva med dem.
Pĺ adressen
http://sanskrit.gde.to/hindi/dict
finns engelsk-hindi-lexikon.
Pĺ adressen
http://http://www.zein.se/patrick/chinsv3p.html
finns översättning av nĺgra kinesiska tecken (se Kinesiska ovan).
Pĺ
http://www.threechords.com/hammerhead/cool_edit_96.shtml
kan du ladda ner ett program som heter Cool_Edit (se Melodier ovan).
Pĺ
http://www.tucows.com/preview/193454
kan du hämta Anvil-Studio, ett freeware-program för att göra
midi-filer.
Här fanns en länk till Kurts hemlighus.
HEMLIGHUSEN RIVNA NOV07!!!
I stället för hemlighus finns nu Kurts hurts pĺ
http://web.telia.com/~u87548829/index.htm
där bland annat svenska och engelska ordlistor som man kan söka i bĺde frĺn början
och slutet av ord. Jag har använt ett par av dessa för att göra stavningsordlistor. De
ligger i zip-mappen i hurtsen. De engelska ordlistorna är baserade pĺ material frĺn
http://www.gutenberg.org/etext/3201
I Kurts hurts finns ocksĺ mĺnga av de ramsor vi, som barn, lärde oss när vi
lärde oss att tala. Ramsor som gav oss vĺr svenska sprĺkkänsla.
Pĺ
http://web.telia.com/~u43309284/spel_nytta.html
finns diverse matnyttigt. Bl a finns där en möjlighet att sortera ord i
bokstavsordning. Du kan t ex ta en vanlig text, klistra in den och fĺ
den omstuvad med orden i bokstavsordning. Men om du använder t ex
mellanslag (=blanktecken) mellan orden sĺ tänk pĺ att ange
mellanslag som "split in".
Pĺ
http://www.matematikersamfundet.org.se/ordlistor.html
finns länkar till ett par matematikordlistor. En av dessa (Vretblad-
Engström) har jag använt till en engelsk-matematisk ordlista som
finns i Ordlist-mappen.
Pĺ
http://tyda.se
kan man ladda ner ett program som fungerar som ett insticksprogram
till Internet Explorer. När man har installerat det kan man hĺlla ner
tangenten Alt och klicka pĺ ett ord. Det ordet slĺs dĺ upp i ett
engelskt lexikon. Det är mycket lätt att slĺ upp ett ord men
uppslagsresultatet täcker helt över sidan och omöjliggör fortsatt
läsning. För att fortsätta mĺste man klicka bort uppslagsresultatet.
Pĺ min gamla dator blir ocksĺ hanteringen seg i nĺgra sekunder efter
ett uppslag. Den största fördelen med det här programmet är att
lexikonet är ganska omfattande. Det brukar ge svar även pĺ ganska
ovanliga ord.
Pĺ
http://hem.passagen.se/eramura/svenska/ordindex.htm
har Mujde Rashid lagt en svensk-kurdisk ordlista. I mappen ordlistor.zip
som ligger under rubriken Lexikoncentral pĺ http://hem2.passagen.se/lean2724)
finns denna ordlista anpassad för att kunna användas som ordlista i
LexSup. I denna version av ordlistan är kurdiska ord skrivna med
latinska bokstäver.
Nationellt centrum för sfi och svenska som andrasprĺk har en hemsida pĺ
http://www1.lhs.se/sfi/index.html
Där finns bl a lästips och länkar.
Pĺ hemsidan
http://matmin.kevius.com/index.html
har Bruno Kevius lagt en matematisk uppslagsbok.
Pĺ hemsidan
http://www.elfdalsasen.com
har Älvdalsĺsens hembygdsförening en ordlista för älvdalska.
Pĺ hemsidan
http://web.telia.com/~u97502328/
har John Josefsson lagt ut en ordlista för Meänkieli. Där finns ocksĺ ett
avsnitt ur hans bok med minnen frĺn Markitta by. Jag har använt hans
ordlista för att göra ett lexikon för Meänkieli.
Pĺ http://www.tkukoulu.fi/~cina/ finns en rysk sprĺkkurs för nybörjare.
Den använder utf8-kodning.
NYTT
====
2009-12-02 Jag har gjort en hel del ändringar i hanteringen av universaltangentbord. Fortfarande
finns en del fel kvar och jag har ännu inte gjort nĺgon bruksanvisning men jag lägger ut det som
finns i befintligt skick. Jag har även bytt ut LexSup134 i "Mĺnadens färdiga mapp".
2009-11-26 Jag har, ett par dagar i förtid, lagt ut december mĺnads färdiga mapp.
2009-11-22 Jag har gjort nĺgra ändringar i tangentbordshanteringen.
2009-11-17 Jag har gjort en del ändringar i tangentbordshanteringen. Det gĺr nu att lägga in
val av tangentbord i teck.tab och jag tänker, men har ännu inte gjort det, lägga in ett sĺdant val
i teck.tab i svkin134 sĺ att LexSup öppnar direkt med Universalbord
2009-11-16 Jag upptäckte att tangentbordet för tvĺbytestecken fungerar bra om man vill
skriva kyrilliska bokstäver med charset 204. Jag har därför döpt om det till Universalbord.
Tills vidare ligger det kvar även under namnet Tvĺbytestecken.
2009-11-14 Jag har kompletterat tangentbordet för tvĺbytestecken sĺ att man även kan
använda shift-tangenten. Det gör att man kan adressera cirka 4 000 tecken. För att se om det
fungerar har jag lagt in nĺgra provtecken i mustecken.tab i svkin134 i det kinesiska
lexikonet.
2009-11-11 Jag har börjat titta pĺ möjligheten att skriva tvĺbytestecken, till exempel kinesiska,
med tangentbordet. I artikeln om Det kinesiska brevet
finns beskrivet hur man använder detta. Jag har ocksĺ lagt till lite till mustecken.tab i
svkin134 i det kinesiska lexikonet.
009-10-22 När jag började med LexSup gällde stränga regler för vilka tecken som fick ingĺ
i filnamn. Jag började därför stuva in ord med främmande begynnelsebokstäver i filer med
godkända namn. Men detta är inte helt problemfritt. Idag kan man använda filnamn med
tecken som ligger även i fjärde nibble. Pĺ sikt kanske man borde övergĺ till lexikon med
filer för fler begynnelsebokstäver än bara latinska bokstäver, siffror och &. Men det bör ske
sĺ att även gamla lexikon förblir användbara. Jag har därför nu gjort sĺ att LexSup först
letar efter en fil med den verkliga begynnelsebokstaven (eller första delen av ett
flerbytestecken). Om inte det ger en exakt träff fortsätter sökningen enligt tidigare regler för
instuvning i filer med godkända namn. Det verkar som om detta fungerar men tala om om
det ger nĺgra problem!! När det gäller insortering, lexikonomvändning och sĺdant fungerar
detta bara delvis.
2009-10-10 Jag har rättat i hanteringen av förhandsvisning av tecken i Musskrift.
2009-10-06 Jag har rättat nĺgra fel i hanteringen av ; vid konvertering mellan 134 och
html-unicode.
Jag har ocksĺ ändrat i programmet FontMap. Det visar nu även UTF8-kod.
2009-10-05 Jag har ändrat principen för hantering av html-unicode i lexikonen. Jag tog inte
med avslutande ; som en del av teckenkoden men nu har jag ändrat sĺ att den ingĺr i
teckenkoden. Det har medfört en del ändringar i kinesiska lexikon och i procedurerna för
"Översätt".
Att ändra i stora lexikon är vanskligt. Skulle man göra nĺgot fel kan det vara mycket svĺrt
att rätta till det när man glömt vad man gjorde. En lösning pĺ det är att använda utvecklingslexikon
som man gör lista ifrĺn och sorterar in när man väl är bergfast övertygad om att de är felfria.
Men för att markera att det finns tilläggslexikon visas begynnelsebokstav även för tilläggslexikon som inte gett nĺgon träff. Om man inte vill ha denna visning kan man nu för tilläggslexikon sätta
uppslagna ordet för begynnelsebokstaven till #?#. Dĺ tas denna och föregĺende post bort.
Jag lägger med ett tomt sĺdant utvecklingslexikon i installationsmappen.
2009-09-25 Jag har lagt in en möjlighet att konvertera mellan charset 134 och html-unicode.
Visserligen gĺr det att göra sĺdan konvertering i Microsofts Word eller via Googles
översättningstjänst men jag har ändĺ tyckt att det kan vara bra att ha möjligheten i
LexSup. Proceduren finns under "Översätt" pĺ huvudmenyn. Konverteringslexikonen ligger
tillsammans med det kinesiska lexikonet. Proceduren fungerar men nĺgra tecken saknas
i lexikonen och den är lite lĺngsam. Pĺ min gamla dator tar det en stund att konvertera en
lĺng fil.
Pĺ grund av platsbrist pĺ den här sidan har jag flyttat det kinesiska lexikonet till min
ekonomisida och lagt en direktlänk dit.
2009-09-22 Jag har nu lagt in möjlighet att nĺ de 100 vanligaste kinesiska tecknen
i charset 134 via musskrift. Jag har ännu inte beskrivit hur man gör i Bruksanvisningar men
i kinesbrev.htm finns en beskrivning av möjligheten.
2009-04-02 Med Musskrift kommer man ĺt hela teckenbyten. Om man väljer ett Charset med
enbytestecken kan man även i Musskrift se vilka tecken man fĺr när man väljer dem. Men om
man är ovan vid Musskrift och om man har en mus med dĺlig precision är det lite svĺrt att
hantera teckenvalet. Jag har därför lagt in en möjlighet att välja mellan KlickMod och MoveMod.
I KlickMod klickar man pĺ det tecken man vill ha. Och nu öppnar Musskrift i KlickMod. Vill man
ha MoveMod fĺr man växla till det.
Jag har ocksĺ rättat ett fel i "Lexikon till lista" och lagt till en möjlighet att byta
första / pĺ varje rad mot @.
2009-03-27 Jag har gjort nĺgra försök med att skriva kinesiska genom att knyta tangentbordet
till kaligrafistreck. Det som finns nu är enbart till för att testa metoden. Om du vill se hur det
fungerar klickar du pĺ Options-Tangentbord-KaligrafiStreck. Jag har ocksĺ lagt till nĺgra
fĺ ord i det isländska lexikonet.
2009-03-24 Jag tänkte att jag skall se om jag kan förstĺ nĺgot pĺ isländska. Sĺ jag hämtade
de texter som Gutenberg har pĺ isländska. Isländska är märkligt eftersom det finns en
nordisk ton i det som man känner igen trots att man ingenting begriper. Sĺ jag tänkte se om
det lilla isländska lexikonet skulle kunna ge nĺgot. Men det medförde att jag upptäckte ett
problem. Gutenberg lagrar HTML-text i Utf-8-format. I den texten är enbart teckenbytens
första halva okodad. Alla tecken i teckenbytens övre halva är alltsĺ kodade och om man
konverterar till HTML-Unicode fĺr man dem i kodad form. Det är OK i en browser men i
lexikonet ligger de som enbytestecken. Jag har därför lagt in en möjlighet att hämta filtrerad fil
och omvandla kodade tecken i första byten till enbytestecken. Det visade sig att lexikonet i
nuvarande skick är alltför litet för att ge nĺgot nämnvärt bidrag till textförstĺelse.
2009-03-20 Jag har gjort en del ändringar när det gäller hämtning av filtrerad fil. Jag har
ocksĺ kompletterat det kinesiska lexikonet med nĺgra ord sĺ att det nu närmar sig 6 000
ord.
2009-03-17 För att komma ifrĺn problemet att hantera stor eller liten begynnelsebokstav
sorteras uppslagsorden för varje begynnelsebokstavsfil med början frĺn andra
bokstaven. Men detta fungerar inte för kinesiska tecken eftersom tecken med olika
inledningsbyte ligger i samma fil. Jag har nu ändrat i Insortering och i Lexikonomvändning
för att fĺ dessa att fungera även i kinesmod. Det börjar bli en hel del som hanteras
annorlunda i kinesmod vilket gör att det är viktigt att veta om LexSup stĺr i kinesmod
eller inte. Jag har därför lagt in att Inordrutans färg växlar till Fuchsia när LexSup sätts i
kinesmod. Jag har ocksĺ ändrat en del i fonthanteringen för att snabba upp hanteringen.
2009-03-16 Jag har ändrat i fonthanteringen för att kunna slĺ upp och se kinesiska
tecken. Jag har ocksĺ rättat nĺgra fel i hur Utfilrutan och Memorutan visas.
2009-03-15 Frĺn Peter Bondessons lexikonprogram (se Länkar ovan) har jag hämtat ett
isländskt, ett grekiskt och ett walesiskt lexikon som jag konverterat till LexSup-
lexikon.
2009-03-11 Ibland kan det vara lättare att skriva kinesiska med charset i stället för med
HTML-Unicode. Jag har gjort en del ändringar för att möjligöra det och kompletterat det
kinesiska lexikonet med ett lexikon för charset 134. Mer om hur man kan använda detta
finns i Det kinesiska brevet.
2009-03-07 Charset, UTF-8, HTML-Unicode, UCS-2 är bara nĺgra exempel pĺ olika sätt att
koda flerbytestecken. Och det vimlar av försök att hantera dessa pĺ ett "smart" sätt vilket
innebär att det är nästan omöjligt att veta vad som händer när man hämtar, ändrar eller
sparar en text. Jag har försökt fĺ nĺgra övergĺngar att fungera men i mĺnga fall blir
inte resultatet vad det borde bli. Testa först innan du använder nĺgon konvertering av
en fil som innehĺller väsentlig information!! Och se till att du har nĺgon back-up-fil!! Än
verkar det vara lĺngt kvar innan drömmen om att UTF-8 skall lösa alla problem blir en sanndröm.
2009-02-28 Det fanns en bug i Insortering som gjorde att det blev fel om rader i insorteringslistan
inte avslutades med mellanslag. Eftersom jag har använt insorteringslistor där raderna avlutats
med mellanslag har jag inte märkt detta förrän nu. Jag har nu försökt rätta till detta och hoppas
att det skall fungera. Men tänk pĺ att alltid ha en backup av lexikon som du ändrar i.
När det gäller kinesiska sĺ motsvaras mĺnga av vĺra vanliga ord av teckengrupper. Men det
är mĺnga gĺnger ett mysterium hur det kinesiska sprĺket kopplat samman begrepp till
teckengrupper. Frĺgan är dĺ hur "Översätt" och "Översätt ordtecken" skall visa tecken som bara
finns som första del i en teckengrupp. Visar man namnet pĺ hela teckengruppen kan det vara
helt fel. Men mĺnga gĺnger kan teckengruppens namn ge en antydan om vad inledningstecknet
stĺr för. Jag har nu gjort sĺ att teckengruppens namn visas med * som avslutning.
2009-02-27 Det kinesiska lexikonet har nu passerat 5 000 uppslagsord. Användbarhet börjar
vid 30 000 ord och dit är det en bra bit kvar. Men det är inte längre häpnadsväckande om
man finner ett ord i lexikonet. Men i kinesiska räcker det inte med en antydan om
ordbetydelse. Man mĺste skaffa sig en känsla för hur tecken och ord sätts samman för
att ge mening. Men man kan nu hämta hem kinesiska texter och börja bekanta sig med dem.
Texter finns bland annat pĺ Gutenberg (se länk under Länkar ovan). Om man hämtar en
text i UTF-8 format kan man med "Arkiv-Hämta filtrerad fil" konvertera den till HTML-Unicode
som lexikonet använder.
2009-02-26 Jag upptäckte att mĺnga vanliga ord inte motsvaras av ett kinesiskt tecken utan
av en teckengrupp. Man kan ju se en sĺdan teckengrupp som en fras men eftersom den
skrivs ihop utan mellanslag fungerar inte fraskontrollen pĺ den. Jag har därför gjort sĺ
under rubrikerna "Översätt" och "Översätt ordtecken" att en fraskontroll alltid görs om
uppslagsordet börjar med &. Under dessa rubriker är ocksĺ fraskontrollen avkortad till
100 bytes i stället för 200 bytes.
2009-02-24 Jag har rättat fel i hanteringen av tecken i Kommentarrutan. Bland annat har jag
lagt in en rensning av rutan frĺn radbörjansmarkering och en ĺterställning av ĹÄÖ. Jag har
ocksĺ ändrat ĺteruppslag med mushjulet sĺ att man rullar nedĺt bland Utordrutorna när man för
hjulet framĺt och aktiverar uppslag när man drar det tillbaka. Teckenhantering är knepig men
jag hoppas att alla ändringar skall fungera OK och att de gĺr pĺ alla datorer. Hör av dig om
du upptäcker nĺgot problem!!! QFZ-funktionen fungerar inte när Översätt lägger kommentarer
i Anmärkningsrutan.
2009-02-23 Jag har rättat en del fel i Översätt. Bland annat fungerade inte ĺteruppslag med
mushjulet pĺ rätt sätt.
2009-02-18 Jag har ändrat en del i konverteringen av Utf-8 till HTML-Unicode. Hoppas det
fungerar som det ska.
2009-02-14 Jag har gjort en del ändringar när det gäller att skriva och läsa kinesiska. Hur man
använder detta finns ännu inte beskrivet i Bruksanvisningar men jag har lagt lite om det i
kinesbrev.htm.
2009-02-12 Jag har lagt in en rubrik som heter "Översätt tecken" under "Internet". Tanken med
den är att man skall kunna se pĺ t ex kinesiska texter sĺ att man ser tecken och översättning
intill varandra. Man hämtar en text kodad i Unicode för html-text i Utfilrutan. Sĺ klickar man pĺ
"Översätt tecken" och fĺr dĺ upp Browserrutan. Utfilrutans text läggs i en fil som heter
LexSupTrans2Qvaolett.htm och Browserrutan navigerar till den. Man ser dĺ tecknen i
Browserrutan. När man klickar pĺ "Översätt nĺgra tecken" skjuts översättningen in i texten
efter tecknet. Man ser alltsĺ i Browserrutan tecknen följda av Lexikon2:s översättningsförslag.
2009-02-10 Sakta,sakta växer det kinesiska lexikonet. Det är nu uppe i c:a
400 tecken. Men för att ett lexikon skall vara intressant mĺste det finnas
texter att skriva och läsa. Under Kinesiska ovan finns nĺgra synpunkter pĺ det.
2009-01-29 Jag har utökat det spanska och det finska lexikonet och bytt ut
det lilla Interlingua-lexikonet mot det större.
2009-01-19 Jag har kompletterat det spanska lexikonet sĺ att det nu innehĺller
cirka 10 000 svenska uppslagsord.
2009-01-14 Jag har lagt in en metod att hĺlla reda pĺ vilka ord som hör samman
i Utfilruta, Översättningsruta och Anmärkningslista. Hur man gör framgĺr av
Bruksanvisningar-Översättning. Det fungerar för det mesta men kan missa om
texten innehĺller vissa specialtecken. Jag har ocksĺ stuvat om lite i det
engelsksvenska lexikonet. För att testa Översätt har jag använt stycken ur
Treasure Island (Skattkammarön) som jag hämtat pĺ http://www.gutenberg.org .
2009-01-10 Jag har lagt in en Anmärkningslista som visas när man kör "Översätt".
I den listas ord som har flera alternativ och/eller kommentarer.
2009-01-06 Jag har lagt ut ett utkast till holländskt lexikon med 800 uppslagsord.
Jag har ocksĺ stuvat om lite i engelsk-svenska lexikonet för att fĺ Översätt att
ge ett mer begripligt resultat.
2009-01-05 Jag har utökat det finska lexikonet frĺn 6 000 till 9 000 uppslagsord
och det kinesiska frĺn 50 till 200. Jag har ocksĺ ändrat en del i programmet för
att göra det möjligt att slĺ upp html-unicode.
2008-12-17 Jag har tittat lite pĺ möjligheten att göra ett utkast till lettiskt
lexikon. Men ett problem är att det lettiska alfabetet innehĺller en del tecken
som inte finns i det engelska alfabetet. Och att använda Unicode i ett program
som skall kunna slĺ upp i lexikon är inte helt enkelt. Jag trodde först att man
bara kunde göra om eventuella Unicode-tecken till baltiskt charset och skriva
och slĺ upp i lexikonen som vanligt. Men i lettiska förekommer tydligen s med
cirkumflex som saknas i baltiskt charset. Jag har i alla fall lagt till en
möjlighet att konvertera Unicode till baltiskt charset.
2008-12-10 Jag har lagt till en möjlighet att spara Översättningsrutan. Den kommer
fram under Arkiv om man har Översättningsrutan framme. Jag har ocksĺ lagt in en
möjlighet att lägga samman listor. Den finns under Lexikonhantering. Om man har
ett antal ord pĺ ett sprĺk och samma ord pĺ ett annat sprĺk kanske man vill göra
en lista där varje ord pĺ det ena sprĺket stĺr pĺ samma rad som motsvarande ord
i det andra sprĺket, det vill säga en lista som gĺr att använda för insortering.
Dĺ kan man använda Listsammanläggning som finns under Lexikonhantering. Jag
har ocksĺ kompletterat det finska lexikonet med ett par hundra ord.
2008-12-07 Jag har rättat nĺgra buggar i Översätt och lagt en länk till Googles
översättningsservice under Länkar ovan.
2008-12-01 Jag har, med stor tvekan, börjat lägga in en möjlighet att "översätta"
nĺgra rader i taget. Den här delen är inte färdig men det som hittills är klart finns
under Översätt pĺ huvudmenyn. Varje ord (eller fras) översätts med lexikonets
första alternativ. Jag provade med en engelsk text som gav rena rapakaljan.
Hittills har jag inte brytt mig om i vilken ordning alternativen har stĺtt i lexikonen.
I mĺnga fall har därför mycket udda betydelser hamnat som första alternativ.
Jag har nu gjort en del ändringar i ensv vilket resulterade i att man kanske kan
ana vad en text handlar om.
2008-10-22 Det är möjligt att Interlingua skulle kunna användas som mellansprĺk
vid tvĺstegsuppslag. För den som vill prova finns nu nĺgra Interlingua-lexikon.
2008-10-12 Jag upptäckte, the hard way, att om man har direktpar aktiverat och
klickar pĺ Arkiv-Nytt sĺ raderas hela den fil som man höll pĺ med. Jag har nu
ändrat sĺ att Arkiv-Nytt tar bort filnamnet och därigenom inaktiverar direktspar.
Jag har ocksĺ börjat se pĺ möjligheten att använda mellansprĺk och som ett första
steg lagt ut ett lexikon till Interlingua. För att fĺ plats med detta har jag flyttat det
engelska lexikonet till min ekonomisida med en direktlänk till det. Det engelska
lexikonet ligger ju i installationsprogrammet sĺ jag tror inte att behovet av att
ha det separat är särskilt stort.
2008-10-07 Jag har ändrat i exit-hanteringen. Det verkade lite fĺnigt att man fick
frĺgan om man ville spara Utfilrutan även om den var tom. Jag upptäckte ocksĺ att
sprĺkbyte kan vara katastrofalt om man har direktspar aktivarat. Sprĺkbyte lägger
ju en text i Utfilrutan och med direktspar försvinner dĺ hela den fil man arbetar med.
Jag har ändrat en del i den här hanteringen och hoppas att den fungerar bättre men
man bör nog undvika att byta sprĺk under pĺgĺende arbete.
2008-09-28 Jag brukar inte använda LexSup för att surfa pĺ nätet. Det är bara om
jag stöter pĺ irriterande redirect eller har behov av lexikonstöd som jag tar till
LexSup. Men ibland händer det att jag hittar adresser som jag vill spara för att
kunna ĺterkomma till. När man stänger LexSup försvinner hela URL-listan. Men jag
har nu lagt in en möjlighet att spara adresser och att ĺtergĺ till dem. Hur man gör
finns beskrivet i Bruksanvisningar - Internet (i slutet).
2008-09-27 Pĺ mina gamla datorer hände det ganska ofta att skriften stoppade upp
när jag skrev lĺnga html-filer med browserrutan framme. Jag har nu försökt ĺtgärda detta
sĺ att normala sparfunktioner aktiveras om inte uppdateringen hänger med.
2008-09-19 Jag har ändrat lite i frasmodshanteringen. Om den inskrivna
frasen inte finns i frasmod2 läggs det inskrivna in i Utfilrutan. Jag har ocksĺ
lagt till nĺgra kinesiska tecken.
2008-04-14 Jag har lagt in en möjlighet att sätta tangentbordet i permanent frasmod.
Jag har även i OrdFras2.tab börjat lägga in nĺgra koder som jag ofta använder när
jag skriver html-text.
2008-04-13 Jag har ändrat sĺ att Utfilrutan fĺr focus när man öppnar LexSup även
om inte muspekaren stĺr pĺ Utfilrutan. Jag har ocksĺ lagt in ytterligare en möjlighet
att sätta tangentbordet i frasmod (frasmod2). Mer om detta under Tangentbord
och Kinesiska ovan.
2008-04-11 Se Tangentbord ovan.
2008-04-08 Jag har lagt in en möjlighet att lägga in en egen teckenuppsättning
för tangentbordet ( se Tangentbord ovan).
2008-04-05 Jag har rättat nĺgra fel i fonterna LexSupCyr1.ttf och LexSupGrek1.ttf
som ligger i installationsprogrammet.
2008-04-03 Jag har lagt ett tangnetbord med grekiska tecken. Jag tänkte
bara lägga bokstäverna med grekisk placering men lĺta alla övriga
tangenter vara oförändrade. Tyvärr finns det en del fel i LexSupGrek1.ttf
som aktiveras när man väljer det grekiska tangentbordet. För tillfället har
jag inte möjlighet att rätta varken detta eller felen i LexSupCyr1.ttf. Tecknen
kommer rätt i browsern.
2008-04-01 Jag har lagt in en möjlighet att ställa om tangentbordet sĺ att
det ger tecken pĺ liknande sätt som ett ryskt tangentbord (Options-
Tangentbord). Ett par tangenter har jag behĺllit pĺ samma plats som
pĺ det svenska tangentbordet. Och ett par tecken (Ё och Щ)
blir lite speciella. Щ hamnar pĺ ´-tangenten vilket innebär att man
fĺr trycka pĺ tangenten tvĺ gĺnger sĺ att man fĺr tvĺ tecken där man tar
bort det ena. Ё saknas t v i LexSupCyr1.ttf men den kommer rätt i
en browser kodad för Windows-kyrilliska tecken. Den skrivs med
tangenten längst till höger i näst översta raden följd av E eller e.
2008-03-29 Jag har gjort nĺgra ändringar i hanteringen av utf-8.
2008-03-28 Jag upptäckte att jag glömt att lägga till avslutande ; pĺ
HTML-unicoden vid konvertering frĺn Utf-8.
2008-03-27 Vissa HTML-texter är kodade enligt utf-8. Utfilrutan i LexSup är
en RichEdit-ruta som inte klarar att hantera utf-8 pĺ rätt sätt. Det medför
att alla sparprocedurer inkl Direktspar förstör utf-8-filer. Jag har nu gjort sĺ att
när du hämtar filer med filnamnstillägget .htm eller .html kontrolleras om de första
2000 bytes innehĺller strängen utf-8. I sĺ fall fĺr du en panel där du kan välja om
du vill ladda in filen som den är eller konvertera den till HTML-unicode. Om du
konverterar den och vill behĺlla originalfilen kan du spara den som oformaterad
fil under ett nytt namn. Tills vidare fungerar konverteringen bara för tvĺ-bytes-tecken.
2008-03-25 Jag har ändrat en del i unicode-hanteringen. I RichEdit finns tvĺ
sätt att ange unicode-tecken. Antingen med \u..? eller genom att i filhuvudet
lägga in en font med charset och sedan anropa denna font för skrivna tecken.
Hur dessa möjligheter fungerar när man hämtar och sparar formaterade eller
oformaterade filer är en hel vetenskap. Jag borde nog skriva lite om det men
det har jag ännu inte gjort.
2008-03-20 Det var ett tag sedan jag använde det ryska lexikonet. När jag nu
skulle använda det enligt beskrivningen i "Ryska posten" upptäckte jag att
uppslag i Lexikon1 inte fungerade. Jag har i nĺgot sammanhang ändrat i
valet av begynnelsebokstav sĺ att det inte fungerar med latinska bokstäver
när man har valt "Främmande Latinskt till Special". Jag har nu ändrat sĺ att
begynnelsebokstaven bara ändras om den ligger i teckenbytens övre
halva och om man inte kastat om sprĺk med dubbelkomma. Det finns ocksĺ
en del problem med ĹÄÖ och med uppslag i det rysk-svenska lexikonet för
vissa begynnelsebokstäver. Jag hade tänkt lösa detta genom att använda
siffror som begynnelsbokstäver. Detta är bara delvis genomfört men jag har
gjort en del ändringar i den riktningen.
Omvandling av rtf-unicode fungerar bara delvis. Sĺ snart man börjar rota i
rtf-formateringen fĺr man de mest otänkbara resultat.
2008-03-18 Jag har rättat nĺgra fel och lagt ut en mapp med lĺngsamma
bokstavsljud till Lära läsa.
2008-03-16 En vacker dag kanske unicodehanteringen fungerar som den skall.
2008-03-15 En del blev fel i hanteringen av unicode. Jag har ocksĺ tänkt om
när det gäller förskjutningsvärde. I stället för att justera in tecknet i
teckenbyten och sedan förskjuta det har jag nu använt totala förskjutningsvärden
och för &# - kodning endast omvandlat om värdet faller inom övre nibble av
teckenbyten. Det gör att man kan ha unicodetecken för t ex matematiska
symboler som förblir opĺverkade om man t ex omvandlar kyrilliska tecken.
Jag har ocksĺ gjort nĺgra ändringar i FontMap som du kan hämta under
rubriken Hämta ovan. Där kan du i Unicoderutan fĺ tecken
som gĺr att kopiera med ctrl-c och klistra in Utfilrutan. Där finns ocksĺ html-koden
för tecknet. Jag har ocksĺ lagt till ett par knappar för att bläddra i Unicoderutan.
2008-03-14 Jag har lagt begynnelsebokstäverna Š och š pĺ S och ändrat en del
pĺ omvandlingen mellan enbytestecken och unicode för html.
2008-03-11 Jag har lagt ut ett lexikon pĺ Meänkieli (Tornedalsfinska). I
Meänkieli används bokstäverna Š och š. Jag har ännu inte rättat till
hanteringen av begynnelsebokstav för att hantera detta. LexSup kan
alltsĺ hänga sig vid dessa bokstäver. Jag ĺterkommer om detta.
2008-03-01 Jag har börjat ta bort nyordshanteringen.
2008-02-15 Jag har rättat nĺgra fel i programmet och jag funderar pĺ att ta bort
nyordshanteringen. Om det kommer in fel i ett lexikon är de nästan omöjliga att
hitta. För att kunna gĺ tillbaka och kontrollera ändringar i lexikon lade jag in
nyordsmarkering sĺ att man kunde hitta nya ord och granska dem om nĺgot verkade
vara fel. Men med möjligheten att använda kompletteringslexikon fick man en
möjlighet att lägga nya ord i ett utvecklingslexikon tills man blev övertygad
om att det var OK att lägga in dem. Jag tror att det är ett bättre sätt att
hantera ändringar. Jag funderar ocksĺ pĺ att ta bort Lexikonaddition. Man kan
i stället göra en ordlista av det lexikon man vill addera och köra Insortering av
denna. En fördel med detta är att det är enklare att granska en ordlista än ett
lexikon.
2008-02-08 Jag har lagt ut en övningstext för Lära läsa.
2008-02-06 Barn som lär sig läsa skulle kanske kunna använda Spelled speech.
Jag har provat att lägga in en Lära-läsa-mod baserad pĺ Spelled speech. Frĺn
Kurts hurts (se LÄNKAR) hämtade jag Kattresan och tänkte använda den som
övningstext. Men med alla ljudfiler och bildfiler blev redan de tvĺ första verserna
för stora för den här hemsidan. Men moden finns nu inlagd och i bruksanvisningen
för Spelled speech finns beskrivet hur man använder den. Jag fĺr fundera mera
pĺ hur jag gör med övningstext.
2008-02-02 Ett problem har varit att Utfilrutan tappar focus när man har scrollat i
Browserrutan. Jag har lagt en smal remsa i Browserrutans överkant som ger
ett extra focusbyte när man för muspekaren frĺn Browserrutan till Utfilrutan. Det
tycks fungera.
2008-01-27 Jag har lagt in en möjlighet att sortera in en ordlista i Stavningsordlistan
(Lexikonhantering-Insortering i Stavningsordlista). Jag har ännu inte hunnit testa
denna möjlighet ordentligt. Använd den med försiktighet och se till att ha back-up.
Jag har ocksĺ via ordlistor och script i Kurts hurts gjort en engelsk stavningsordlista.
För att använda denna hämtar du den, döper om mappen Stavning i den mapp
där du installerade LexSup, lägger in den hämtade mappen i den mapp där du
installerade LexSup och döper om den till Stavning.
2008-01-23 Jag har rättat till scrollningen för "Spelled speech", "Sök i Utfilruta"
"Byt ut i Utfilruta" och "Sök stavfel".
2008-01-21 Jag har börjat göra en stavningskontroll. Ĺterkommer med mer
om detta men delvis fungerar det och en ordlista ligger nu med i installations-
programmet.
2008-01-16 Jag upptäckte att det inte gick att byta fil med "Hämta Utfil" om
man hade droppat en fil pĺ ikonen. Det visade sig bero pĺ att "Hämta Utfil"
anropade en startprocedur. Jag minns inte varför jag lagt in detta anrop men
jag har nu tagit bort det. Hoppas det fungerar.
2008-01-10 Jag har lagt in en möjlighet att visa bildserier även i lexikon
(se bruksanvisning). Jag upptäckte ocksĺ att mappen med olika sprĺk
för labels mm fallit bort ur installationsprogrammet sĺ jag har lagt tillbaks
den. Jag har även lagt in nĺgra ord i utkastet till uppslagslexikon.
2007-12-27 Jag har gjort en fontkarta som jag kallar FontMap. Den finns
under rubriken "HÄMTA" ovan. Frĺn början hade jag tänkt att lägga in den
som en del i LexSup men den blev sĺ lĺng sĺ jag tror att det är bättre att
ha den som ett separat program. Det gör det ocksĺ enklare att ha den igĺng
samtidigt som man arbetar med ett annat program.
2007-12-22 Jag har svĺrt att lära mig genus för tyska substantiv sĺ jag
provade med att ange genus med färgkodade utordrutor men vid närmare
eftertanke kom jag till att det npg är bättre att lägga in orden i bestämd form
sĺ att man kanslĺ upp dem eller använda "Visa lexikon" för att se genus.
För att prova detta har jag ändrat filen Aalt.lex i svensk-tyska (svty) lexikonet.
En del saknas för att jag inte direkt fann nĺgon tillförlitlig uppgift om genus
men man kan se hur det är tänkt.
2007-12-16 Jag har ändrat lite när det gäller färgkodade Utordrutor. Man
skulle kunna använda färgkod för att ange ordklass, genus, böjningsform
mm. Men för att ĺteruppslag skall fungera mĺste man dĺ ta bort färgkoden
frĺn Utordrutans text. Det har jag nu gjort. Jag har ocksĺ lagt in en möjlighet
att ange färg med en siffra vilket innebär att alla färger blir tillgängliga (utom
färgvärdet 1 som används för att ange att en bokstav används som färgkod).
För mörka färger syns texten dĺligt och jag har därför lagt in en koll av
bakgrundsfärg som ställer om textens färg till vitt om bakgrunden är mörk.
Det här kan ge problem med att Delfi inte är helt pĺlitligt när det gäller
fontfärger men det lilla jag har hunnit kolla sĺ verkar det fungera. Jag har
funderat pĺ att lägga in färger för ordklasser o dyl men det borde göras
efter ett genomtänkt system sĺ att man kan lära sig vad färgerna betyder
och där har jag inget bra förslag. Hör gärna av dig om det!!
2007-12-05 Älvdalska är ett sprĺk (eller en dialekt) som talas i Älvdalen i
norra Dalarna. Sprĺket är intressant bl a för att det bevarat en del av den
äldre svenskan. Älvdalsĺsens hembygdsförening har pĺ sin hemsida
http://www.elfdalsasen.com
en ordlista som jag använt för att göra ett LexSup-lexikon.
2007-11-15 Jag har lagt in en möjlighet att sortera ordlistor o dyl
(Options-Sortering).
2007-11-03 Jag upptäckte ett fel i programmet som gjorde att Browserrutan
pĺ vissa datorer visades förskjuten till höger. Det gjorde att jag fann att det
kan finnas tillfällen när man vill kunna se Utfilrutans vänsterkant under
Browserrutan. Jag har därför lagt Browserrutans vänsterkant 10 pixels frĺn
skärmkanten sĺ att man kan lägga Utfilrutans Textyta med mindre vänster-
marginal sĺ att dess kant syns. Jag har ocksĺ ändrat i LexSup1.ini sĺ att
LexSup efter installationen startar med vänstermarginalen 6 pixels.
2007-10-30 Möjligheten att skriva i Utfilrutan och direkt uppdatera en
Utfil som visas i Browserrutan ger en möjlighet att hantera andra alfabet.
I Bruksanvisningar-Internet (bara i den version som ligger i installa-
tionsprogrammet) har jag beskrivit hur man kan använda detta.
2007-10-22 Det har varit problem med Sök och Byt under Redigera. Ett
av problemen har varit att dessa använder textmarkering som i LexSup
används även för andra ändamĺl. Jag har nu ändrat sĺ att dessa
möjligheter fungerar om än inte exakt pĺ samma sätt som i alla andra
program. Hur de fungerar finns beskrivet i Bruksanvisning. Jag har bara
ändrat i programmet i installationsmappen.
2007-10-18 Jag har rättat (hoppas jag) nĺgra buggar i Textkontroll.
2007-10-11 Jag har provat att lägga in teckensprĺksbilder.
2007-10-10 Jag har lagt ut ett utkast till Uppslagslexikon, tagit bort
en visa och en klockfil ur Litteraturmappen och gjort nĺgra smĺändingar
programmet.
2007-10-07 Jag har lagt in en möjlighet att infoga uppslagsordet i
en internetadress och en möjlighet att i lexikon lägga en mapp som
heter web och i den lägga en fil som heter web.txt och som innehĺller
generella internetadresser som visas vid varje uppslag.
2007-10-03 Möjligheten att ha Utfilrutan tillgänglig samtidigt som
browserrutan visade sig öppna en intressant möjlighet att redigera
html-text. Om man öppnar en html-text i Utfilrutan och via Internet-
Browse och Sök öppnar den Browser-rutan kan man skriva i Utfil-rutan
och direkt se i Browserrutan hur det blir. Om Browserrutan visas, om
den är nedsänkt och om dess URL är samma som Utfilrutans filnamn
skriver Utfilrutan direkt till Utfilen som visas i Browserrutan. Pĺ min
gamla dator är detta en operation som inte gĺr blixtsnabbt och man
fĺr därför inte skriva alltför snabbt. Av nĺgon anledning missar ocksĺ
focus-valet sĺ att man kan fĺ höja och sänka browserrutan för att fĺ
focus att hamna pĺ Utfilrutan. Eftersom texten skrivs direkt till Utfilen
är procedurerna för att spara fil avaktiverade i detta läge.
2007-10-03 Jag upptäckte att det kan vara praktiskt att ha tillgĺng
till Utfilrutan utan att behöva stänga browsern. Jag har därför lagt
in en knapp som heter Sänk (bredvid Stäng browser) som sänker
browserrutan sĺ att Utfilrutan blir tillgänglig.
2007-10-02 Jag har lagt in en möjlighet att färgkoda utordrutorna.
Detta är tänkt för kommande speciallexikon som t ex biologiskt
artlexikon. Ett första utkast till ett biologiskt artlexikon finns
som skofza-lexikon under rubriken Lexikon ovan. För att fĺ plats
med det har jag plockat bort en del ur Litteraturmappen.
2007-09-29 Frĺn Peter Bondessons norska ordlista har jag gjort ett
norskt lexikon. Där finns en del ord som jag undrar över men det fĺr
ligga tills vidare. Hör av dig om du hittar nĺgot konstigt i det.
Jag har lagt in en möjlighet att lĺta browsern söka efter
länkar till lexikonmappen i stället för att söka pĺ Internet. Om man
lägger en länk där första tecknet är > i stället för < söker LexSup
i lexikonmappen efter en fil med det namn som finns inom citationstecken
i länken. Ett exempel pĺ detta finns pĺ uppslagsordet Fermat i
matematiklexikonet.
2007-09-27 Jag har lagt ut ett lexikon som slĺr upp i Bruno Kevius
matematiska uppslagsverk matmin. LexSup är petigt när det gäller
bokstavordning och det kan förekomma en del fel där ett felplacerat
ord skymmer följande ord. Men jag lägger ut det i det skick det
nu befinner sig för att rätta fel när jag hittar dem.
2007-09-26 Jag har rättat (hoppas jag) nĺgra smĺfel i programmet.
2007-09-24 Jag har lagt in en möjlighet att använda internetlänkar som
uppslagna ord i lexikon. En sĺdan länk visas som vanligt i en Utordruta.
Om den har < som första tecken tolkas den som en länk när man aktiverar
den. Den första del av texten som stĺr inom " " används dĺ som URL och
LexSup öppnar browsern.
2007-09-19 Jag tänker lägga om lexikonen. I stället för att lägga ett
flertal lexikon i installationsprogrammet tänker jag lägga alla lexikon
som separata lexikon som man kan lyfta in i den mapp där man installerat
programmet. Fördelen med det är att man slipper fĺ med lexikon som man
inte är intresserad av och att man lätt kommer ĺt lexikonen om man vill
hämta dem för nĺgot annat än att använda dem ihop med LexSup.
2007-07-23 Det finns ett problem med kommentarer i tilläggslexikon. För
huvudlexikonet visas kommentarer till det uppslagsord som LexSup finner
men vad skall visas för tilläggslexikon om detta uppslagsord avviker frĺn
inordet? Jag har nu ändrat sĺ att kommentarer frĺn tilläggslexikon hör till
inordet och bara visas om detta finns i kommentarfilen.
2007-07-22 Jag har börjat lägga in en möjlighet att använda utvecklings-
lexikon. Att utbyta stora lexikon, t ex via Internet, innebär en del problem.
Det är nästan omöjligt att granska ett lexikon pĺ mĺnga tusen ord.
Om det innehĺller fel och man lägger samman det med ett annat stort lexikon
gĺr det sedan inte att hitta och rätta felen. Det kan därför vara bättre att
utbyta kompletteringar i form av tilläggslexikon pĺ nĺgot hundratal ord
som man kan granska och provanvända tills man är övertygad om att det
är lämpligt och ofarligt att lägga samman tilläggslexikonet med huvud-
lexikonet. Jag har ännu inte hunnit provanvända denna möjlighet men jag
lägger ändĺ ut den och hoppas att den inte innehĺller alltför mĺnga
buggar.
2007-05-28 Frĺn Mujde Rashids ordlista har jag gjort ett kurdiskt
LexSup-lexikon som ligger med i installationsprogrammet (mapparna
svkul och kulsv). I detta är kurdiska ord skrivna med latinska bokstäver.
2007-05-26 Jag har i mappen ordlistor.zip pĺ http://hem2.passagen.se/lean2724)
lagt en kurdisk ordlista som gjorts av Mujde Rashid.
2007-05-22 Jag har lagt in en möjlighet att lägga info-filer i lexikonmappar och i
LexSup:s startmapp. Det gör att man kan lägga in information om ett lexikon
och/eller reklam o dyl.
Jag har ocksĺ kompletterat browsern med en möjlighet att surfa bakĺt.
2007-04-20 Jag har lagt in en möjlighet att lägga in kommentarer via
Insortering. Det är lite bristfälligt provat men det tycks fungera.
2007-04-16 Jag har lagt in en länk till tyda.se.
2007-04-05 Det har blivit enklare (inte mycket men nĺgot) att slĺ upp
ord frĺn browsern.
2007-03-24 Jag har lagt WordGumbos holländsk-engelska ordlista
i zip-filen med ordlistor och flyttat den filen till passagensidan.
2007-03-23 Jag har lagt till en möjlighet att använda midi-filer
i Spelled speech.
2007-03-15 Jag har rättat ett fel i hanteringen av teckengrupper i
spelled speech och gjort en del ändringar enligt Melodier ovan.
2007-03-14 Se Melodier ovan.
2007-03-11 Jag har ibland saknat möjligheter att i LexSup blanda olika
fonter i samma dokument. Det har bl a handlat om att skriva rubriker o dyl.
Och att skilja ut avsnitt med annan färg eller med kursiv text. I början
tyckte jag inte det spelade nĺgon roll. Det finns ju andra program som
klarar detta och det var inte för detta som jag skrev LexSup. Men nu har
jag ändĺ lagt in Tecken som en rubrik pĺ huvudmenyn som gör att man i
Utfilrutan kan ändra font inne i ett dokument och spara det som rtf-fil.
Pĺ mina gamla datorer fungerar det inte alltid. Vissa varianter pĺ
fonter gĺr inte. Egentligen hade jag tänkt försöka använda det för att
välja charset för inkommande tecken och kanske kunna slippa använda
memoruta men det fungerar inte pĺ mina datorer sĺ jag behĺller memorutan
tills vidare.
2007-03-10 Ännu sĺ länge stuvar jag om hejdlöst i kinesiska lexikonet och
i de delar av LexSup som hanterar det. Hoppas det inte skadar nĺgot annat.
Jag har flyttat det som lĺg i 1alt.lex till 2alt.lex. Det är nog sĺ att
man fĺr göra olika lexikon för olika charsets sĺ jag kallar det här för
kinsv136 för att visa att det är gjort för charset 136.
2007-03-08 Jag har gjort en del ändringar för att göra det möjligt att
skriva och läsa kinesiska. Hoppas att det inte har förstört nĺgot annat.
Ännu ĺterstĺr mycket. Jag lägger med ett kinesiskt-svenskt lexikon (kinsv).
Jag har hittills bara hittat 5 ord som jag tror att jag vet vad de betyder.
Det kan ju verka lite meningslöst att lägga ut ett lexikon med bara 5 ord
men det visar hur jag har tänkt fortsätta. Anm: För att Inordrutan skall
kunna ta emot kinesiska tecken mĺste man byta till charset 136 i Startvärden.
2007-03-06 Se KINESISKA ovan.
2007-03-01 Jag har lagt in en möjlighet att med hjälp av # som radslut
hĺlla samman texter i ordlistor och ordböcker.
2007-02-17 Jag har ändrat lite i browserns adresshantering.
2007-02-16 Jag har rättat nĺgra smĺfel i programmet.
2007-02-07 Jag upptäckte att under resans gĺng har en del ord fallit bort
ur de engelska lexikonen. Jag har med "Lexikon till lista" gjort om gamla
lexikon till listor och kört dessa med "Nya listord" mot dagens lexikon.
Resultatet av detta har jag via "Insortering" lagt in i lexikonen.
Även det svensk-finska lexikonet visade sig behöva samma behandling och
det finsk-svenska tycks ha drabbats av en total katastrof. Jag har nu gjort
ett nytt finsk-svenskt lexikon.
2007-02-06 Jag har börjat göra ett utkast till en svensk-lettisk ordlista.
2007-02-04 Jag har ĺtergĺtt till att göra ändringar i den version som
ligger i installationsprogrammet pĺ denna sida.
Det förekommer en del olika sätt att hantera icke-latinska alfabet. I
t ex WordGumbos ryska ordlistor används en metod att med tags ange
Unicode-värde för varje bokstav och dessutom ange transkription till
latinsk motsvarighet. Det blir lĺnga filer som blir helt ohanterliga
när det gäller att slĺ upp i dem. Jag har därför modifierat "Options-
Unicode till enbytestecken" sĺ att man kan omvandla dem till listor
med kyrilliska bokstäver enligt LexSupCyr1. Men de innehĺller en del
radskift och det blir en del rester av tags kvar som man mĺste hantera
manuellt för att kunna använda dem som ordlistor för LexSup.
2007-02-01 Jag har lagt in LexSup med browser i installationsprogrammet
och flyttat det gamla installationsprogrammet till
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
Jag har ännu inte gĺtt igenom alla lexikon för att kontrollera alla
ords placering efter att jag ändrat uppslagsfunktionens sätt att hantera
bokstavsordning. Det kan alltsĺ finnas felplacerade ord i lexikonen.
Jag har även gĺtt igenom lite mer av ordboken men den nya versionen
ryms inte pĺ den här sidan sĺ även den ligger pĺ lean2724.
2007-01-31 Jag har gjort en del ändringar i LexSupInt med syfte att
komma fram till en standard för vad som är bokstavsordning för stora,
smĺ och ovanliga bokstäver.
2007-01-29 Jag har gjort en del ändringar i LexSupInt.
2007-01-25 Hantering av begynnelsebokstav är inte helt enkel när
man har stora och smĺ bokstäver och när man behöver använda bokstäver
utöver dem som ingĺr i engelska alfabetet. Jag har börjat försöka fĺ
ordning pĺ detta men jag lägger bara in ändringar i versionen med
browser (LexSupInt) som finns pĺ
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
2007-01-20 Jag har provat att lägga in en browser i LexSup. Tanken
är att man skall kunna surfa med lexikonstöd. Programmet är lĺngt
ifrĺn färdigt och jag har haft en del problem med browsern pĺ vissa
datorer. Jag lägger därför detta program i en särskilt zip-fil pĺ
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
2007-01-18 Pĺ Internet förekommer ofta ordlistor i tabellform. I
Bruksanvisningen för Musskrift har jag beskrivit hur man kan kopiera
sĺdana till ordlsitor som gĺr att använda i LexSup.
2007-01-16 Jag har gjort nĺgra smĺändringar och lagt till en början till
ett polskt lexikon. Konverteringsprogrammet i extralex.zip kan nu
konvertera ryska skriven med ljudmotsvarande latinska bokstäver till
kyrillisk text enligt LexSupCyr1. Denna konvertering är emellertid
inte helt fullständig och den kan ge en del fel men den fungerar
hjälpligt för WordGumbos ryska listor.
2007-01-08 Jag har gjort en del ändringar för att förbättra tvĺstegs-
uppslag. Den här typen av ändringar är riskabla. Risken är stor att
de ger oväntade problem men en del tycks i alla fall fungera som förut.
Frĺn WordGumbos ordlistor har jag gjort ett isländskt och ett polskt
lexikon som man kan använda tillsammans med ett engelskt lexikon för
tvĺstegsuppslag. Polska använder en del skrivtecken som saknas i
västerländska enbytes-fonter. Man använder därför Charset 238 för
polska. Jag kan ingen polska och kan därför inte se hur WordGumbo har
hanterat detta, jag har bara gjort som det stĺr i deras listor.
2007-01-06 Jag har gjort ett konverteringsprogram för att omvandla
bl a ordlistor frĺn WordGumbo till insorteringslistor för LexSup (se
Om mellansprĺk). Jag har även ändrat en del pĺ
hanteringen av begynnelsebokstav och rättat ett fel i Musskrift.
2007-01-04 Se Om mellansprĺk ovan.
2006-12-30 Jag har gjort lite ändringar av bildhanteringen för att kunna
lägga in bilder i ordboken.
2006-12-27 Jag har nu gĺtt igenom ordboken. Den vimlar av gamla socialister
som jag aldrig hört talas om och det finns nog en hel del fel i den. Dels
finns det inscanningsfel och dels har nog sprĺkbruket ändrats en del
sedan 1927. Pĺ nĺgra stället har jag gjort smärre ändringar men i stort
sett följer den den inscannade versionen. Jag tänkte undan för undan
komplettera med nytt material. Att den innehĺller en del förlegat material
är ju egentligen inte nĺgot fel. För den som söker gammal information
är den kanske en guldgruva.
2006-12-19 Jag har gjort nĺgra kompletteringar pĺ engelska lexikonen.
2006-12-17 Jag har sorterat in en svensk ordlista frĺn wordgumbo i
det engelska lexikonet. Det nya lexikonet ligger i installationsprogrammet.
2006-12-16 Jag har lagt in nĺgra intressanta länkar under rubriken
LÄNKAR.
2006-12-15 Jag har lagt in lite mer av ordboken.
2006-12-14 Jag har lagt in en möjlighet att ändra lexikon till
ordlistor. Förut gick detta att göra genom att göra en lexikon-
omvändning som samtidigt gav en ordlista enligt utgĺngslexikonet.
Men jag behövde göra en del listor utan att ha nĺgot behov av
lexikonomvändning och när jag gjorde listor frĺn mycket smĺ
lexikon blev begynnelsebokstav och filslut en stor del av listorna.
Detta gäller fortfarande för listor som görs vid lexikonomvändning
men den nya proceduren rensar bort dessa delar av en lista.
Jag har ocksĺ lagt in ett danskt lexikon. Hur det är med kvaliten
beror pĺ kvaliten hos de källor jag använt och den är jag osäker
om. Hoppas att det är nĺgorlunda tillförlitligt.
2006-12-09 Jag har lagt ut början pĺ en ordbok. Se under rubriken
Ordbok ovan.
2006-11-21 Jag har nu hittat ett sätt att hantera ĺteruppslag frĺn
Lexikon2 som förefaller fungera bĺde under Windows98 och WindowsXP och
även vid uppslag av delar av ord.
2006-11-20a Det visar sig att Windows98 och WindowsXP hanterar ändringar
av markerad text lite olika. Vid ĺteruppslag frĺn Lexikon2 mĺste man
ta bort textmarkeringen sĺ att inte det markerade ordet raderas. I
Windows98, men inte i WindowsXP raderas dĺ texten i utordrutorna sĺ att
det inte finns nĺgot att slĺ upp i Lexikon1. Jag har nu ändrat för att
avhjälpa detta men den nya placeringen av cursorn blir olika sĺ att
sista bokstaven i det markerade ordet raderas i Windows98. Jag ĺterkommer
om denna bug.
2006-11-20 När man kör Lexikonomvändning fĺr man en omvändning av
lexikonets glosdel. Vad som menas med omvändningen av kommentardelen
är däremot oklart. Jag vill ju hela tiden ha kommentarerna pĺ mitt
modersmĺl. Men om man gör en omvändning för att fĺ ett lexikon för
andra med annat modersmĺl borde man ju göra helt nya kommentarer. Sĺ
kommentardelen följer inte med till det nya lexikonet. Men ibland skulle
man vilja komma ĺt kommentarerna när man har det omvända lexikonet som
Lexikon2. Ett sätt att göra det kan vara att använda ĺteruppslag även
för Lexikon2. Jag har därför lagt in möjlighet att även vid uppslag i
Lexikon2 bläddra med 4 och 0 samt att välja alternativ för ĺteruppslag
i Lexikon1 med 1 , 2 eller 3. Pĺ det sättet kommer man alltsĺ ĺt
kommentarerna i Lexikon1.
2006-11-18 Alltid finns det nĺgot att ändra. Jag har gjort nĺgra ändringar
av musskrift.
2006-11-16 Jag har rättat nĺgra smĺfel. Den Memo-ruta som täcker över
utfilrutan när man använder musskrift och ett charset>10 har fĺtt en
lite annan bakgrundsfärg än den vanliga utfilrutan. När man använder
ett charset som är ganska likt det vanliga alfabetet, t ex 238 för
sprĺk som polska, kan det vara svĺrt att veta om man ser Memo-rutan
eller den vanliga Utfilrutan. Med lite olika färg pĺ dem gĺr det att
se vilken som är framme. Vid utskrift försvinner Memo-rutans bakgrundsfärg
för att skrivaren skall slippa skriva ut den. Färgen ĺterkommer när
utskriften avslutas.
2006-11-15 Jag har gjort lite förbättringar (hoppas jag) pĺ musskrift och
ändrat lite i spelled speech.
2006-11-06 Jag la egentligen in Musskrift som ett sätt att i nödfall
kunna komma ĺt tecken som är svĺra att nĺ via tangentbordet, t ex
japanska och kinesiska tvĺ-bytes-tecken. För att det inte skulle, mer
än nödvändigt, inkräkta pĺ annat gjorde jag rutorna sĺ smĺ som möjligt.
Men det betyder att man mĺste använda en mus med hög precision. Med
min gamla mus som galopperar över skärmen är det nästan omöjligt att
skriva med denna musskrift. Jag har därför lagt in en möjlighet att
expandera musskriften till dubbla storleken.
2006-10-30 Jag har lagt ut en svensk-dansk ordlista.
2006-10-27
Jag har ändrat lite pĺ hanteringen av första bokstaven i uppslags-
ordet. Jag hoppas det skall fungera bättre utan att ställa till
med oväntade problem. Jag har ocksĺ rättat ett fel i hanteringen
av "Flera Alternativ" när man använder tilläggslexikon.
2006-10-25 Jag har flyttat sammanslagna lexikon för engelska och
finska frĺn nyalex.zip till installationsprogrammet. Mina gamla
lexikon för engelska och finska är därmed borttagna.
Jag har ändrat lite pĺ hanteringen av reservrader i etikettfilerna.
Det gör att de gamla mapparna Lang1 och Lang2 inte längre fungerar.
Använd dem som nu finns i installationsprogrammet.
2006-10-23
Jag har börjat göra det möjligt att välja sprĺk för etiketter och
bruksanvisningar. Än sĺ länge fungerar det bara för nĺgra fĺ etiketter
och jag har ännu inte översatt nĺgra bruksanvisningar men man kan se
hur det är tänkt. Jag har tagit bort mappen Anvisningar. De filer
som lĺg där finns nu i mappen Lang\Lang1. Jag har ocksĺ ändrat lite
pĺ hanteringen av Inordruta, Uppslagsord och Utordrutor för att göra
det möjligt att komma ĺt text som inte ryms i rutan. Hur detta är
gjort finns i Bruksanvisning under rubriken Fraser.
2006-10-21
Om man vill provanvända ett lexikon eller tillfälligt ha tillgĺng
till ett speciallexikon kunde det vara lämpligt att kunna lägga till
ett tilläggslexikon till det vanliga lexikonet. Det är nu möjligt att
lägga in sĺdana tilläggslexikon. Under Bruksanvisningar-Lexikonhantering
finns beskrivet hur man gör. Jag hoppas att detta inte stör andra
funktioner men man bör nog undvika att göra ändringar i lexikon
via LexSups ändringsfunktioner sĺ länge man har tilläggslexikon
inlagda.
2006-10-17
I nĺgra fall släckte jag utordrutor utan att tömma dem. Det
medförde att gamla utord kunde dyka upp under fel uppslagsord
t ex vid insortering. Jag har nu försökt rätta detta.
2006-10-14
Jag har nu tagit bort "lexsupfiler". Och jag har gjort nĺgra
ändringar i hanteringen av ordlistor och lagt ut nĺgra ordlistor
som jag hittat pĺ nätet och modifierat för att passa för LexSup.
2006-10-12
Jag har gjort nĺgra ändringar i hanteringen av ordlistor och
hoppas att det fungerar utan att ställa till nĺgra problem med
andra delar av programmet.
2006-10-11
Det verkar som om installationsprogrammet fungerar och den version
som ligger i "lexsupfiler" börjar bli förlegad sĺ jag tänker ta
bort den.
Jag har kompletterat anvisningarna för ordlistor.
2006-10-10
Jag har lagt in en möjlighet att ersätta Lexikon1 med en ordlista
med godtyckligt format. Enda kravet pĺ ordlistan är att det är en
radindelad textfil. Vid uppslag i en sĺdan ordlista söks listan
igenom efter uppslagsordet och de rader som innehĺller det visas
i kommentarrutan.
2006-10-08
När man vill titta pĺ en fil med Hackerbild är man ofta bara
intresserad av ett litet avsnitt. Kanske vill man se filhuvudet
eller ett par rader för att se hur en text är formaterad. Det
är ju dĺ onödigt att ga igenom hela filen. Jag har därför gjort
sĺ att Hackerbilden öppnar med 20 16-bytes rader. Vill du se mer
fĺr du ändra i rutorna för frĺn och till.
Jag har flyttat "Sök i Utfilrutan" frĺn Options till Redigera.
Jag tänkte ocksĺ lägga in en möjlighet att byta ut strängar i
Utfilrutan men det är nĺgot fel med ReplaceDialog i min Delphi
sĺ jag har stängt av den funktionen.
Jag har även gjort en del smĺändringar som jag hoppas är
förbättringar.
2006-10-05
Jag har lagt samman Peter Bondessons svensk-finska lexikon med
mitt gamla. Resultatet finns i mappen med nya lexikon. Där finns
även ett swahili-svenskt lexikon som är gjort genom lexikon-
omvändning.
2006-10-01
Ibland händer det att man tar in en fil i Utfilrutan och fĺr ett
oväntat resultat. Man frĺgar sig dĺ vad det egentligen stĺr i
filen. För nĺgra ĺr sedan vimlade det av hackerprogram som man
kunde använda för att syna en fil närmare men när jag nu letar
efter nĺgot sĺdant hittar jag ingenting och det bästa vore ju
om jag direkt i LexSup kunde granska filen. Sĺ jag har under
Arkiv pĺ huvudmenyn lagt in en möjlighet att visa en fil i
en hackerbild. Inläggningen strulade en hel del men jag hoppas
att resten av programmet fungerar som vanligt. Under Windows 98
kan man bara titta pĺ korta filer.
Peter Bondesson har pĺ sin hemsida
http://web.telia.com/~u85724740
lagt ett lexikonprogram och ett antal ĺtkomliga lexikon. Lexikonen
äri de flesta fall betydligt bättre än mina och de skulle ganska
lätt kunna anpassas för att fungera under LexSup. Jag ĺterkommer
om detta.
2006-09-24
Det är skillnad mellan hur Windows 98 och Windows XP hanterar
filnamn. I Windows XP fungerar inte Delphi-funktionen FileExists
för filnamn som innehĺller html-tag. Jag har ändrat hanteringen
för att fĺ spelled speech att fungera även för tags under XP. Jag
har ocksĺ försökt fĺ läsningen att inte haka upp sig vid ny rad
som följs av mellanslag. Fortfarande hänger läsningen sig vid
ny rad följd av mellanslag och tag men det är kanske sĺ ovanligt
att det är acceptabelt.
Jag funderar pĺ att ta bort sudoku-hanteraren för att fĺ mer
plats för annat.
2006-09-21 em
De fonter som fanns i mappen med fonter finns nu i den font-mapp
som ligger i installationsprogrammet. Jag har därför permanent
tagit bort mappen med fonter.
2006-09-21
Jag har ändrat lite i paushanteringen och jag har lagt till
hantering av nĺgra specialtecken i spelled speech. Men ljudfiler
är skrymmande och jag har tills vidare fĺtt lov att ta bort
mappen med fonter eftersom jag annars överskrider utrymmet pĺ
denna hemsida.
2006-09-20
Bokstavsljuden för t , p och k gav obehaglig överstyrning av
ljudenheten. Jag har nu dragit ner dem lite. Och jag har lagt
till ande och ing som exempel pĺ stavelseljud.
2006-09-17
Jag har nu lagt in möjlighet att i mappen för bokstavsljud lägga
filer med flerbokstavsljud. Det gĺr alltsĺ att lägga in sje-ljud
i en fil som heter sj.wav och det gĺr att lägga in stavelseljud.
Programmet letar nu ocksĺ i lexikonfilerna efter en ljudfil som
motsvarar vad som stĺr i editrutan. Finns det en sĺdan läses den
i stället för bokstav-för-bokstavs-läsning.
2006-09-15
Jag börjar nu fĺ lite ordning pĺ spelled speech och lägger därför in
det i installationsprogrammet. Det innebär att jag kan lägga tillbaka
demon, fonter och sudokuhanteraren.
2006-09-14
Jag har gjort försök med spelled speech.
Spelled speech diskuteras ibland som ett hjälpmedel för blinda men man
brukar avfärda det med att det är varken skrift eller tal. Men det är
ju egentligen inte nĺgot argument. Spelled speech är spelled speech och
kan användas av dem som finner det användbart.
Inläggningen av spelled speech har ännu en del buggar och jag är osäker
pĺ hur man bör göra en del saker sĺ jag lägger bara ut det kompilerade
programmet tillsammans med en mapp med bokstavsljud. Du kan hämta det
genom att klicka pĺ
spelledsp.zip Borttaget! Ingĺr nu i installationsprogrammet.
För att fĺ plats med detta pĺ hemsidan har jag tagit bort den demo som
lĺg här (med ett föredrag om energi). Denna demo har jag lagt pĺ min
huvudsida och under rubriken HÄMTA ovan finns en länk dit. Jag har ocksĺ
flyttat zip-filen med fonter till huvudsidan och länken under HÄMTA gĺr
alltsĺ dit. Det visade sig att detta inte räckte sĺ jag har även flyttat
sudokuhanteraren till min huvudsida och länkat dit.
Bokstavsljuden finns i en mapp som heter spsp. LexSup letar efter denna
i mappen för lexikon 1, mappen för lexikon 2, öppningsmappen och i utfil-
mappen. För att LexSup skall hitta den mĺste du alltsĺ lägga den pĺ nĺgot
av dessa ställen.
Bokstavsljuden är ännu sĺ länge bedrövliga men med Windows Ljudinspelare
kan du göra egna och bättre bokstavsljud.
När du klickar pĺ Spelled speech pĺ huvudmenyn öppnas en panel med en
editruta och tvĺ knappar (Nästa och Stäng). LexSup startar vid cursorn
i Utfilrutan och lägger in bokstäverna fram till nästa mellanslag i
editrutan. Och därpĺ läser LexSup texten i editrutan med spelled speech.
När du klickar pĺ Nästa läggs nästa ord in och läses.
Du kan skriva i editrutan. När du skriver en bokstav läser LexSup den.
om du avslutar texten med ett mellanslag läser LexSup hela texten i
editrutan (p g a en bug dubbelläses sista bokstaven). Om du avslutar
med ytterligare ett mellanslag läggs texten i editrutan in vid cursorn
i Utfilrutan.
Om du klickar pĺ ramen runt editrutan läggs det som stĺr i editrutan
in som uppslagsord och LexSup hämtar översättningsförslag frĺn Lexikon 1
och lägger in upp till tre förslag i editrutan varpĺ dessa läses med
spelled speech.
Under pĺgĺende läsning blockeras alla andra funktioner och om du t ex
klickar pĺ nĺgot händer ingenting förrän läsningen är klar.
2006-06-09
Windows vimlar av "smarta" lösningar som med nästan osviklig intuition
ger fel resultat. När det gäller fonter är väl avsikten att om en font
eller ett visst tecken saknas sĺ skall Windows automatiskt hitta bästa
tillgängliga alternativ. Men det innebär att resultatet kan bli nästan
vad som helst. Jag har gjort nĺgra försök att skriva devanagari och
japanska tecken vilket fungerar nĺgot sĺ när pĺ min version av Windows XP
men inte alls under Windows 98. Jag lägger i alla fall programmet i
befintligt skick i installationsprogrammet och lĺter det ligga där över
sommaren.
Intressant information om japanska finns pĺ
http://www.japanska.se
Om du där slĺr upp ett ord i ordlistan och sedan klickar pĺ tecknet fĺr
du nĺgot som kallas Kanjiuppslagning som ger en hel del information om
tecknet.
2006-06-05
Jag har börjat skissa pĺ ett sätt att hantera japanska och kinesiska
skrivtecken med hjälp av Musskrift. Hur man använder det som hittills
är klart framgĺr av bruksanvisningen för LexSups Musskrift. Det är bara
den version som ingĺr i installationsprogrammet som har denna möjlighet.
2006-06-01
Jag har kompletterat och rättat musskrift. Den nya versionen ligger i
installationsprogrammet men ej lexsupfiler.
2006-05-20
En fördel med Musskrift är att man nĺr fler tecken än med tangentbordet.
Speciellt när man behöver hantera flera alfabet eller alfabet med mĺnga
tecken kan detta vara en viktig fördel. Jag tänkte därför lägga in
en förenklad version av Musskrift i LexSup. Denna är ännu inte färdig
och än mindre avlusad men jag lägger ändĺ in det som nu finns i den
version som ingĺr i installationsprogrammet.
Vid uppslag i lexikon försvinner musskriftfältet och ersätts av en
blĺ ruta mellan Utordrutorna och Kommentarrutan. Klicka pĺ denna för
att ĺterställa musskriftfältet.
2006-05-18
Ännu ĺterstĺr mycket innan LexSup kan hantera Devanagari men det fĺr
bli en uppgift för mörka höstkvällar. Jag lägger i alla fall ut det
som nu finns. Det har medför en hel del ändringar och det finns
risk att nĺgot annat skadats. Jag har ocksĺ utgĺtt frĺn att fonten
xdvng.ttf finns installerad. Jag har därför lagt in xdvng.ttf i
installationsprogrammet sĺ att den installeras. Men jag har inte
ändrat de filer som ligger i lexsupfiler. Skulle den version som
ligger i installationsprogrammet inte fungera finns alltsĺ den
föregĺende versionen i lexsupfiler.
xdvng.ttf innehĺller sĺ mĺnga tecken att det inte finns utrymme att
samtidigt ha ett latinskt alfabet inom en byte. För att kunna slĺ i
ett lexikon mellan ett sprĺk som använder latinskt alfabet och ett som
använder Devanagari mĺste man alltsĺ växla font. Microsoft har i
Windows lagt in "smarta" sätt att automatiskt välja bästa font. Ibland
fungerar detta bra men när man vill styra valet av font ger det ofta
oväntade och oöbskade resultat. Programmet är skrivet i Delphi6 och
provat pĺ en dator med en ganska gammal version av Windows XP Professional.
Du kan välja xdvng som font och fĺr dĺ Utfilrutan i Devanagari. Du kan där
skriva text genom att skriva de tecken som motsvarar Devanagari-tecknen i
xdvng. Eftersom denna font har fler tecken än vad tangentbordet direkt kan
adressera mĺste du använda tangentbordsförskjutning för att nĺ vissa tecken.
Detta är naturligtvis möjligt men knappast praktiskt användbart. Här krävs
en bättre lösning!
Om du vill slĺ upp ett ord med dubbelkomma skriver du tvĺ kommatecken och dĺ
gĺr Utfilrutan och Inordrutan över i latinskt alfabet medan Utordrutorna gĺr
över i Devanagari. När du väljer ett ord eller skriver SPACE gĺr Utfilrutan
tillbaka till Devanagari.
xdvng använder ett charset som heter SYMBOL. Delphi6 klarar inte hantering av
markerad text i detta charset. Om du markerar ett ord i texten gĺr därför
Utfilrutan över till latinskt alfabet innan ordet slĺs upp i Lexikon2. Du
ĺtergĺr genom att klicka pĺ nĺgon Utordruta eller genom att föra mushjulet
framĺt. Det här ger ett problem när du vill dubbelklicka pĺ ett ord i
stället för att markera det. Vid första klicket gĺr Utfilrutan över till
latinskt alfabet och eftersom tecknen inte tar samma utrymme som tidigare
hamnar inte cursorn under muspekaren. Du fĺr alltsĺ klicka, flytta muspekaren
till cursorn och dubbelklicka.
I princip skulle det nu gĺ att börja göra ett lexikon frĺn ett sprĺk med
latinska bokstäver till t ex Hindi. Ett omvänt lexikon däremot kräver en del
ändringar när det gäller hantering av begynnelsebokstäver.
GLAD SOMMAR!!!
2006-05-16
DEVANAGARI
Sanskrit,Hindi och en del andra indiska sprĺk använder en teckengrupp
som heter Devanagari. Man kan som i det latinska alfabetet ha ett tecken
för varje sprĺkljud eller som i kinesiska och japanska alfabetet ett
tecken för varje ord. Sprĺkljudstecken blir sĺ fĺ att ett par alfabet
ryms inom en byte. Ordtecken blir sĺ mĺnga att det är helt uteslutet
att försöka rymma dem inom en byte. Devanagari är ett mellanting som
kan kallas ett stavelsealfabet.
Pĺ adressen
http://sanskrit.gde.to/hindi/dict
finns engelsk-hindi-lexikon. Där används en font som heter xdvng.ttf för
hindi-texten. Jag har hämtat den gratis och utgĺr frĺn att den inte
är copyright-skyddad sĺ jag lägger med den i installationsfilen för
LexSup. Du hittar den i den mapp där du packar upp LexSup. Men jag
har inte lagt in den sĺ att den installeras vid uppackningen. Vill du
ha den mĺste du själv installera den i Windows.
xdvng.ttf använder ett charset som heter SYMBOL. Av nĺgon anledning
lyckas inte LexSup ställa om till detta charset när jag kör det under
min version av Windows XP (men under Windows 98 fungerar det). Jag
har därför lagt in ett par rader i källkoden som ställer om charset
för fontnamnet xdvng vilket medför att det fungerar under XP.
xdvng använder sĺ stor del av byten att det latinska alfabetet inte
ryms. Byter du font till xdvng byts alltsĺ alla tecken till Devanagari.
Som det nu är fungerar alltsĺ inte lexikonprincipen med ord pĺ tvĺ
sprĺk.
2006-05-10
Jag har lagt in en ĺteruppslagsfunktion.
LexSup använder tvĺ lexikon. När man slĺr upp ett ord i ett av dessa
fĺr man ett eller flera alternativ. Jag har nu gjort sĺ att när men
väljer ett av dessa slĺs det valda alternativet upp i det andra lexikonet.
Det här kan vara ett sätt att undvika en del misstag och det öppnar en
möjlighet till tvĺstegslexikon.
Antag att du vill läsa en text pĺ hindi och lyckas hitta ett användbart
lexikon för hindi-engelska. Dĺ kan du lägga detta som Lexikon2 och ensv
som Lexikon1. Om du markerar ett ord i texten slĺs det upp i Lexikon2 och
om du väljer ett av de alternativ du fĺr upp i Utordrutorna slĺs det upp
i ensv till svenska. I slutet pĺ Bruksanvisning finns beskrivet hur detta
fungerar.
2006-04-16
Om man vill lägga in mer omfattande kommentarer och/eller
kommentarer som innehĺller matematiska symboler, index, exponenter
och sĺdant fungerar inte den vanliga kommentarrutan. Jag har
därför lagt in en möjlighet att använda helfilskommentarer. Hur
man gör finns beskrivet i Bruksanvisning.
Jag har lagt in nĺgra enstaka ord pĺ swahili. Det är tydligen sĺ
att swahili använder förleder i stället för ändelser för att skilja
mellan olika böjningsformer. Det kan ju innebära ett problem när
maa slĺr upp ord efter begynnelsebokstav. Om man tar med alla
böjningsformer bör det ju fungera men man borde nog veta lite mer om
det här än vad jag gör.
2006-04-13
Pĺ min tekniksida
http://web.telia.com/~u87701228
har jag lagt en text om begreppen "Här och Nu". Du hittar den under
"NYTT" pĺ menyn.
Den ligger som en .zip-fil tillsammans med LexSup och visar hur jag
tänkt mig att man kan skicka filer tillsammans med LexSup.
För att se hur filhuvud och alla tags ser ut kan du hämta nu.rtf med "Arkiv -
Hämta oformaterad utfil".
2006-04-09
Under rubriken Litteratur har jag lagt en länk till projekt Runeberg.
2006-04-07
Jag har kompletterat rtf-mallen genom att i filhuvudet lägga in fonten
Arial som är en font där anrop av tecken som ligger utanför den första
byten sker med backslash-u-siffra-? . Det kan vara bra att ha med en
sĺdan font om man t ex vill komma ĺt matematiska symboler. Vilka siffror
som ger vad hittar du i filen för html-tecken.
Det visade sig att Windows XP och Windows 98 hanterar richtext pĺ lite
olika sätt. Jag har använt Windows XP men de anrop av tecken och charsets
som jag har använt fungerar inte under Windows 98. Problemet är väl av
övergĺende art eftersom användningen av Windows 98 troligen minskar när
det blir allt mer omodernt. Jag tror inte det är mödan värt att försöka
göra nĺgot ĺt det.
2006-04-04
Jag har börjat se lite pĺ användning av olika charsets och andra
formateringsmöjligheter. Det kräver nog en hel del ytterligare eftertanke
men nĺgra synpunkter finns i "Om textformatering" under "Bruksanvisningar".
I den mapp där du installerar LexSup finns ocksĺ en rtf-mall som du
kan använda för att se hur man kan använda charsets.
2006-03-29
I en äldre version (LexSup1) fanns en möjlighet att skriva in och aktivera
tags i en text, t ex för att skriva index och exponenter. Denna möjlighet
orsakade en del problem sĺ jag tog bort den. Ett annat sätt att hantera
tags är att lägga in dem i en fil med oformaterad text som läses som
richtext. För att underlätta detta har jag ändrat hanteringen av text-
formatering. Det gĺr nu att under Arkiv hämta och spara oformaterad text.
Jag har ocksĺ under Bruksanvisningar lagt in lite om textformatering och
tags.
2006-03-20
Jag har gjort en demo för att visa hur man kan lägga ihop en text med
bilder och lexikon. Den gĺr att hämta genom att klicka pĺ
Demo1 1,1 MB
Det är ett föredrag som jag höll vid SET 2006-03-16. Packa upp det, kör
lexsup.exe och klicka pĺ de röda figurmarkeringarna för att se figurerna.
Som vanligt när man försöker använda nĺgot upptäcker man en del problem
och uppläggningen av demon har lett till att jag ändrat en del i hanteringen
av ini-filer.
2006-03-19
Jag har lagt till möjligheten att även använda jpg-bilder.
När man gjorde insortering frĺn lista hände det ibland att programmet
slog upp och lade till nĺgra ord ur nĺgot nyligen använt lexikon. För att
komma ifrĺn detta har jag ändrat sĺ att insorteringen sätter det
reulterande lexikonet som aktuellt lexikon. Hoppas det fungerar.
2006-03-12
Jag har ändrat procedurer för att ta bort radslut och tags och jag har
lagt till en möjlighet (Options - lägg in radslut) att lägga in radslut.
Dessa nya procedurer arbetar enbart med texten i Utfilrutan och
pĺverkar inga diskfiler förrän du sparar resultatet.
Ibland vill man ändra bredden pĺ en text med fasta radslut. Det gĺr
nu att använda LexSup för det. Ta in texten i Utfilrutan, ta bort
radsluten, ändra textrutans bredd och lägg in radslut. Ev kan du
behöva göra en del manuella komletteringar.
Jag har lagt till nĺgra uppslagsord i början av t i svfin och jag har
ändrat filsluten i det lexikonet.
2006-03-04
Jag har nu tagit bort LexSupK. Jag har även tagit bort Nya lexikon och
Lexikon eftersom de senaste varianterna av lexikonen ingĺr i installations-
programmet. Det börjar bli lite trĺngt pĺ hemsidan och det är onödigt att
dubbellägga information.
Jag har börjat skissa lite pĺ ett lexikon pĺ Swahili och hittat lite
mellan engelska och swahili som jag utgĺr frĺn. Det har medfört att jag
använt Insortering, Lexikonaddition och Lexikonomvändning och hittat en del
fel i dessa procedurer. Bl a nyordsmarkerade Lexikonaddition även
upplslagsord vilket gjorde att man mĺste ta bort nyordsmarkeringarna innan
LexSup kunde hitta dem. Och filsluten är ett stort problem. Det är helt
otroligt hur mĺnga varianter det kan bli beroende pĺ hur filer avslutas.
Jag har nu gjort sĺ att Varje fil skall avslutas med
.a˙˙˙ .b˙˙˙
Filavslutning Filavslutning ......
och vid Lexikonaddition, Insortering eller Lexikonomvändning överförs inte
filsluten frĺn ingĺende filer om inte dessa enbart kopieras. I stället
avslutas filer med standardavslut. Av befintliga lexikon har jag rättat
sven och lagt in rätt filslut. De övriga kommer jag att rätta sĺ snart
jag fĺr tid till det.
Ett problem var ocksĺ att programmet hängde sig om kommentarfiler saknades.
Jag har nu ändrat detta sĺ att det tycks fungera.
För att underlätta uppläggning av nya lexikon har jag även lagt med ett
tomt lexikon. Och för att visa hur man kan lägga upp en lista för insortering
har jag lagt med min första lista för swahili (lista1.txt). För att hitta
svenska ord att utgĺ frĺn när man börjar pĺ ett nytt lexikon har jag
använt en lista över de tusen vanligaste orden i romaner. Den innehöll
en hel del egennamn och böjningsformer. Jag har försökt sortera bort dem
och gjort en lista som ligger med som svenskord.txt.
2006-02-21em
Jag har rättat nĺgra smĺfel i Bruksanvisningen och lagt in den nya versionen
i lexsup.zip (men inte i lexsupfiler.zip). Jag funderar pĺ att rensa bort en del frĺn
den här sidan. LexSupK skrevs vid en tid dĺ det förekom att man skickade
filer via disketter pĺ 1.44 MB. Det var dĺ viktigt att hĺlla nere storleken pĺ
programmet. Men det här är nog inte nĺgot problem idag. Pĺ en CD kan man
ju lika gärna lägga LexSup. Det finns därför ingen anledning att LexSupK tar
upp plats här pĺ sidan. Likasĺ är lexikon som jag uppdaterat och lagt in i
LexSup inte aktuella i särskilda mappar.
2006-02-21
Jag har ändrat i LexSup för att det skall gĺ att lägga programmet
pĺ en CD och köra det därifrĺn. Jag har även lagt in en möjlighet
lägga en ini-fil tillsammans med en textfil sĺ att ini-filen körs när
man hämtar textfilen (ini-filen skall ligga i samma mapp som
textfilen och heta lexsup.ini).
2006-02-16
Jag har även lagt in en möjlighet att i ljudfilen lägga textfiler med
länkar till filer som läggs in i den i Windows inbyggda mediaspelaren.
När du skriver en sĺdan länk mĺste du även ta med filnamnstillägget.
Det ger en möjlighet att ta med alla typer av filer som mediaspelaren
kan hantera det vill säga även videoklipp av typen .mpg. Du kan
lägga en fullständig adress som länk men problemet med det är
att den förmodligen inte fungerar pĺ nĺgon annan dator än din
egen. LexSup letar därför även i ljudmappen som hör till Lexikon2
och Utfilen efter en fil med det namn du angett som länk. Det här
möjliggör illustration av begrepp med längre ljud- eller video-
sekvenser. Exempel hittar du i ref.rtf.
2006-02-15
Jag har kompletterat LexSup med möjlighet att i Ljudmappen
även lägga uppslagbara filer av typen .mid , .cda och .mp3.
Det har väl ingen nämnvärd användning för lexikonstöd men det
var ganska lätt att lägga in och jag hoppas att det inte
förstörde nĺgot annat. För att prova hur det och bildvisningen
fungerar kan du använda en text som jag lagt in under
Litteratur. Ladda ner Texter 2,3 MB och
hämta filen ref.rtf som ligger i mappen ref som i sin tur
ligger i mappen Leif Andersson.
2006-02-14
Jag har gjort en del ändringar i LexSup och kompletterat det svensk-finska
lexikonet. Ändringarna i LexSup beskriver jag i Bruksanvisingen pĺ följande
sätt:
Bildvisning
========
LexSup kan visa bilder knutna till uppslagsord i Lexikon2.
.
Lägg en mapp i mappen för Lexikon2 och döp den till "bild".
För varje uppslagsord frĺn Lexikon2 letar LexSup i denna
mapp efter en bild som heter uppslagsordet följt av ".bmp".
Om det finns en sĺdan fil visas bilden upptill till höger pĺ
skärmen. Om du klickar pĺ bilden förstoras den och om du
dubbelklickar pĺ den förstorade bilden ĺtergĺr den till litet
format. Du kan ta bort bilden med Options - Dölj bild. Om
du klickar där ändras texten till Visa bild och bilder visas
bara i en sekund för att därefter försvinna. Du kan även
ta bort bilden genom att klicka pĺ kommentarrutan. Om
bilden är stor och skymmer kommentarrutan dubbel-
klickar du pĺ den sĺ att den blir liten sĺ att du kommer
ĺt kommentarrutan.
.
Det finns även möjlighet att lägga in en serie bilder som
visas i 0,2 sekunder vardera. Du sätter dĺ en nolla framför
namnet pĺ första bilden, en etta framför nästa bildnamn
och sĺ vidare. Du kan ha upp till en nia framför bildnamnet.
.
Smĺ bilder har formatet 180x120 och stora 600x400. Det
därför lämpligt att avpassa bilder sĺ att de passar till detta
format. Bilderna mĺste vara bitmapbilder.
.
Bildvisning kan även användas för att lägga in bilder i en
text. Det mest eleganta är naturligtvis att, som i Word eller
pdf lägga in bilder inbäddade i text men det fungerar inte
pĺ enkla textfiler. LexSup erbjuder en annan möjlighet. Man
kan i samma mapp som textfilen ligger lägga en mapp som
heter bild och i denna lägga in bilder som LexSup kan
hämta genom att man klickar pĺ ord som motsvarar
bildernas filnamn. För dessa bilder gäller samma regler
som för bilder i lexikon.
.
LexSup letar först efter bild i lexikonet och därefter
i den mapp där Utfilen finns. En bild i Utfilmappen har
alltsĺ prioritet framför en bild i lexikonet.
.
Ljud
===
Pĺ liknande sätt som LexSup hanterar bilder kan du
lägga in ljudfiler knutna till uppslagsord i Lexikon2. Du kan
alltsĺ ange uttal med hjälp av ljudfiler.
.
I mappen för Lexikon2 lägger du en mapp och döper den
till "ljud". För varje uppslagsord frĺn Lexikon2 letar LexSup
i denna mapp efter en ljudfil som heter uppslagsordet följt
av ".wav". Om det finns en sĺdan fil sänds den till
ljudkortet via mediaspelaren. Ljudfiler skall vara i wav-format.
.
Genom att lägga en mapp som heter ljud i samma mapp som
Utfilen kan du lägga in ljud i en text pĺ liknande sätt som du
lägger in bilder.
.
Fraser
=====
.
Det som i ett sprĺk anges med ett ord kan i ett annat sprĺk
anges med en fras. Det är alltsĺ viktigt att kunna ha med
fraser i ett lexikon. När det gäller uppslagna ord är problemet
bara att en fras kan vara längre än vad som ryms i Utordrutan.
Men om den ryms inom kommentarrutan kan man dĺ se den
genom att klicka pĺ "Visa Lexikon".
.
När man läser en text och markerar ord för att öppna Lexikon2
kan man markera flera ord för att se om de finns som fras. Om
man markerar ett ord genom att dubbelklicka pĺ det söker
LexSup bara efter det ordet men om det följs av en fras
(= ett uppslagsord som innehĺller mellanslag) blir ramen kring
Utordrutorna gul vilket signalerar att man bör klicka pĺ
"Visa Lexikon" för att se vilken fras som ligger efter ordet.
.
När man använder dubbelkomma öppnas Lexikon1 sĺ snart
man avslutar ett ord. Men om ordet följs av en fras i Lexikon1
blir ramen runt Utordrutorna gul och man kan hitta frasen
genom att klicka pĺ "Visa Lexikon"
2006-02-02
Jag har lagt in en möjlighet att visa bilder i LexSup. Tanken var frĺn början
att prova möjligheten att göra ett universal lexikon till bilder i stället för
översättningsord. Men det är en enorm uppgift och det finns nog närmare liggande
användning för bildvisning.
Om man vill göra en uppslagsbok behöver man kunna lägga in bilder. Bilder gör
ocksĺ att man kan ĺstadkomma ABC-böcker för barn som skall lära sig att läsa
och för vuxna som skall lära sig läsa pĺ ett nytt sprĺk. Man kan lägga upp
övningstexter med klickbara ord som ger bilder. Man kan t ex använda annan
färg pĺ klickbara ord. Det gĺr inte att skriva text med annan färg i LexSup
men du kan ta in en textfil i WordPad och ändra färg pĺ ord. Du markerar dĺ
det ord du vill ha i annan färg och klickar pĺ symbolen efter F K U i
WordPad:s huvud. Du fĺr dĺ möjlighet att välja färg. Spara sĺ filen i
.rtf-format sĺ kan du använda den i LexSup.
Bilder knyts till uppslagsord i Lexikon2. För att visa hur det fungerar
har jag i engelsk-svenska lexikonet (ensv) lagt in bilder pĺ uppslagsorden
run och table. För att se hur det fungerar laddar du ner LexSup, installerar
det, skriver run och dubbelklickar pĺ det eller table och dubbelklickar pĺ
det. Hoppas det fungerar som det ska.
Jag har ocksĺ lagt in en mapp som heter Anvisningar där jag lagt de bruks-
anvisningar som ingĺr i LexSup. Tanken är att de skall vara ĺtkomliga för
utskrift o dyl.
2006-01-28
Jag har försökt rätta en del fel i LexSup när det gäller lexikonhantering.
Det finns mĺnga möjligheter till programkrasch pĺ grund av olika fel i
lexikon och när man ändrar för att lösa ett problem finns alltid risken att
nĺgot annat krĺnglar. Tala om om du hittar nĺgot fel!!!
Jag har lagt in en procedur för att räkna antal ord i lexikon. Den gör även
en kontroll av att inte lexikonet innehĺller tomrader. Denna procedur finns
under "Lexikonhantering" - "Räkna ord i Lexikon1".
Det svensk-finska lexikonet har jag kompletterat med en del uppslagsord
som börjar pĺ s. Där har jag ocksĺ försökt lägga in kommentarer pĺ det
sätt som jag har tänkt mig i ett komplett lexikon. Detta nya svensk-finska
lexikon och dess omvändning har jag lagt in i installationsprogrammet.
2006-01-08
Jag har rättat nĺgra fel i LexSup och hoppas att det inte gett nĺgra nya fel.
Rensa nyord fungerade inte för uppslagsord pĺ Ĺ, Ä, och Ö beroende pĺ
skrivfel i källkoden. Ett försök att lägga in kompletteringar av kommentarer
medförde att programmet hängde sig när det inte hittade kommentarfil eller
när det försökte lägga in kommentarer efter sista uppslagsordet. För att
komma ifrĺn problem med filslut avslutar jag filerna med ett uppslagsord
som bestĺr av begynnelsebokstaven följd av ööö. Det fungerar inte för
främmande alfabet som gĺr förbi ö men det fĺr duga tills vidare.
Jag har, med hjälp av Lexikonomvändning gjort ett finsk-svenskt lexikon och
lagt in aktuella lexikon i installationsprogrammet. De lexikon som ligger i mappen
"nyalexikon" är alltsĺ inaktuella men mappen fĺr ligga kvar tills det blir dags att
ändra den.
2005-12-29
Jag har gjort ett utkast till ett svensk-finskt lexikon. Jag började med att utgĺ
frĺn det svensk-ryska lexikonet vilket samtidigt gav mig tillfälle att rätta en del
fel i detta. Men arbetet gick lĺngsamt och för att komma igenom övergick jag till
att bara ta ord ur en uppställning över de 1000 vanligaste orden i romaner. En
hel del av dessa är böjningsformer och namn sĺ det är betydligt mindre än 1000
ord och lexikonet blev glest för de bokstäver där jag använde detta. För X, Z , W,
Ĺ, Ä och Ö har jag inte lagt in nĺgot alls. Det har alltsĺ en hel del brister men det
är en början för den som vill skapa sig ett eget lexikon. I det svensk-ryska har
jag bara rättat för de begynnelsebokstäver där jag utgick frĺn detta lexikon.
Sĺväl det svensk-finska som det rättade svensk-ryska lexikonet finns i mappen
Mappen Nya lexikon är borttagen eftersom den blivit inaktuell
Pĺ min huvudsida,
http://web.telia.com/~u87703726
under rubriken "Böcker" har jag lagt det som är klart av "Hur fiungerar din värld?"
och "Världen - Ägarens handbok":
2005-10-22
Jag har kompletterat svensk-engelska lexikonet genom att köra "Textkontroll"
(finns under Lexikonhantering) pĺ "Hur fungerar din värld?". Det gav en
del nytt men mycket ĺterstĺr ännu. Och det visade en del problem med
hantering av böjningsformer, namn, ordsammansättningar mm. Men jag lägger ut
det som jag gjorde i den nya mappen
Mappen Nya lexikon är borttagen eftersom den blivit inaktuell
Där finns ocksĺ ett försök att komplettera det svensk-tyska lexikonet. Här
finns fler problem. Bl a frĺgan om hantering av tyskt y och om stor eller
liten begynnelsebokstav för substantiv. Som det nu är finns det inte nĺgon
enhetlig linje i dessa frĺgor.
OBS!! I dessa lexikon ligger nyordsmarkeringarna kvar. Om du vill använda
dem för att göra lexikonomvändning eller lexikonaddition mĺste du först
rensa bort nyordsmarkeringarna. Det kan du göra med "Rensa nyord" som finns
under Lexikonhantering.
2005-10-02
Jag har lagt ut det som hittills är klart av bokutkastet "Hur fungerar din
värld?". Det finns under
Texter 2,3 MB
i mappen Leif Andersson. Tyvärr är jag ännu inte klar med figurerna.
Jag har ocksĺ ändrat lite pĺ hur LexSup öppnar dokument med filnamnstilläggen
.rtf och .trs.
2005-09-14
Jag har gjort försök med att lägga in ljudfiler för att kunna ange uttal.
Detta fungerar pĺ följande sätt: Om du markerar eller dubbelklickar pĺ ett
ord letar programmet efter det i Lexikon2. Om det hittar ordet visar det
översättning och ev kommentarer. Därefter letar det i den mapp som
innehĺller Lexikon2 efter en mapp som heter ljud och i denna letar det efter
en fil med ett namn som bestĺr av det markerade ordet med filnamnstillägget
.wav. Finns det en sĺdan fil startar ljudspelaren och spelar upp filen. Därvid
dyker det upp tvĺ knappar längst upp till höger pĺ skärmen. En med grön pil
som används för att upprepa uttalet och en med en röd rektangel som
används för att ĺterställa ljudspelaren sĺ att man kan upprepa uttalet.
Ljudfiler tar stor plats och det är knappast realistiskt att försöka sprida
uttalsfiler via en hemsida. Tanken är att sĺ smĺningom distribuera dem via
CD eller DVD och att göra det möjligt för den som sĺ vill att själv lägga in
uttalsexempel. Ett exempel pĺ användning kan vara följande:
Antag att du undervisar i Svenska för invandrare och har elever med engelska
som modersmĺl. Eleverna kommer dĺ att använda ett engelsk-svenskt lexikon
(ensv) som Lexikon1 och ett svensk-engelskt lexikon (sven) som Lexikon2. När
de i en svensk text dubbelklickar eller markerar ett ord söker dĺ programmet
i Lexikon2 efter en uttalsfil. Genom att spela in ett antal ord och lägga in
dessa i en mapp som heter ljud i den mapp som innehĺller Lexikon2 kan du
dĺ ĺstadkomma att de fĺr fram uttal för de ord som du anser att de kan
behöva hjälp med. Du kan pĺ detta sätt ĺstadkomma lexikon som är anpassade
till de texter som ni använder som övningstexter.
I den version som jag nu lägger ut ingĺr denna möjlighet och i lexikonmappen
sven finns en mapp som heter ljud där det finns nĺgra ord. Ljudkvaliten pĺ
dessa är dĺlig och det är bara nĺgra enstaka ord men tanken med dem är
att visa hur denna möjlighet kan användas.
Denna version innehĺller även de ändringar som jag gjorde i LexSupNy. Jag har
därför tagit bort LexSupNy. Jag hoppas att detta skall fungera men det
finns alltid en risk att ändringar ger oväntade problem, t ex att ett anrop av
ljudspelaren inte fungerar pĺ din dator. Skulle du rĺka ut för det är jag
tacksam om du hör av dig.
2005-06-08
Jag har lagt till en möjlighet att köra en teck.tab-fil i samband med att man
byter font. Och sĺ har jag rättat till nĺgra fel i förhoppning om att det inte
skapat nĺgra nya.
2005-06-07
Jag har gjort nĺgra ändringar av LexSup. Hantering av fonter för specialalfabet
är ett problem. Jag hade lagt in i själva programkoden hantering av kyrilliskt,
grekiskt och arabiskt alfabet. Men när jag började titta pĺ runor, pĺ alfabet
för hindi och sanskrit, pĺ alfabet för samiska och t o m för alfabet för spanska
inser jag att det inte gĺr att lägga en sĺdan hantering i programkoden. Man mĺste
finna nĺgon metod att hantera olika fonter pĺ annat sätt.
Jag har nu provat att använda en fil som heter teck.tab som jag lägger i
lexikonet för sprĺk som kräver speciell font. LexSup kontrollerar dĺ om det i
Lexikon1 finns en fil som heter teck.tab. Gör det det läser LexSup in den och
aktiverar det specialalfabet som finns angivet där. I lexikonet svry finns en
sĺdan fil där du kan se hur den är gjord.
Jag har ocksĺ lagt in en möjlighet att ändra höjden pĺ textytan pĺ skärmen.
Sĺdana här ändringar är alltid riskabla. Jag har gjort nĺgra tester med det
ändrade programmet men det finns risk att det krĺnglar i nĺgra avseenden. Bl a
ligger rester av den gamla hanteringen kvar. Hör av dig om du stöter pĺ nĺgot
som krĺnglar. Men under sommaren kan det vara problem att nĺ mig sĺ jag lĺter
den gamla versionen ligga kvar tills vidare. För att ladda ner den nya
versionen klickar du pĺ
(Jag har tagit bort LexSupNy. Se texten ovan)
Runor 2005-04-07
----------------
Jag har gjort en font för att skriva med runor i LexSup. Du kan
ladda ner den med
LexSupRun1.ttf
eller med hela fontpaketet
(Fontmappen borttagen. De fonter som ingick finns i installationsprogrammet)
Jag har utgĺtt frĺn tre varianter av runor.
Urnordiska runor
Stungna kortkvistrunor
Danska 16-typiga runraden
Urnordiska runor
................
Den 24-typiga urnordiska runraden har jag hämtat frĺn
Wikipedia uppslagsord Runor.
(http://sv.wikipedia.org/wiki/Runor)
Den omfattar följande tecken
finns bland mycket annat en beskrivning av varje runas innebörd.
När det gäller stungna kortkvistrunor har jag följt Kalle
Runristares anvisningar för moderna runstenar som jag hämtade
pĺ hans hemsida
http://www.runristare.se
Sedan dess har han ändrat hemsidan men det jag dĺ hittade har jag
använt för att göra fonten LexSupRun1 som installeras via LexSups
installationsprogram. Runorna ligger pĺ tangentbordets versaler,
alltsĺ med shift. Använd Caps Lock och "Option - Främmande Latinskt
till Special" för att skriva med dem.
Pĺ adressen
http://sanskrit.gde.to/hindi/dict
finns engelsk-hindi-lexikon.
Pĺ adressen
http://http://www.zein.se/patrick/chinsv3p.html
finns översättning av nĺgra kinesiska tecken (se Kinesiska ovan).
Pĺ
http://www.threechords.com/hammerhead/cool_edit_96.shtml
kan du ladda ner ett program som heter Cool_Edit (se Melodier ovan).
Pĺ
http://www.tucows.com/preview/193454
kan du hämta Anvil-Studio, ett freeware-program för att göra
midi-filer.
Här fanns en länk till Kurts hemlighus.
HEMLIGHUSEN RIVNA NOV07!!!
I stället för hemlighus finns nu Kurts hurts pĺ
http://web.telia.com/~u87548829/index.htm
där bland annat svenska och engelska ordlistor som man kan söka i bĺde frĺn början
och slutet av ord. Jag har använt ett par av dessa för att göra stavningsordlistor. De
ligger i zip-mappen i hurtsen. De engelska ordlistorna är baserade pĺ material frĺn
http://www.gutenberg.org/etext/3201
I Kurts hurts finns ocksĺ mĺnga av de ramsor vi, som barn, lärde oss när vi
lärde oss att tala. Ramsor som gav oss vĺr svenska sprĺkkänsla.
Pĺ
http://web.telia.com/~u43309284/spel_nytta.html
finns diverse matnyttigt. Bl a finns där en möjlighet att sortera ord i
bokstavsordning. Du kan t ex ta en vanlig text, klistra in den och fĺ
den omstuvad med orden i bokstavsordning. Men om du använder t ex
mellanslag (=blanktecken) mellan orden sĺ tänk pĺ att ange
mellanslag som "split in".
Pĺ
http://www.matematikersamfundet.org.se/ordlistor.html
finns länkar till ett par matematikordlistor. En av dessa (Vretblad-
Engström) har jag använt till en engelsk-matematisk ordlista som
finns i Ordlist-mappen.
Pĺ
http://tyda.se
kan man ladda ner ett program som fungerar som ett insticksprogram
till Internet Explorer. När man har installerat det kan man hĺlla ner
tangenten Alt och klicka pĺ ett ord. Det ordet slĺs dĺ upp i ett
engelskt lexikon. Det är mycket lätt att slĺ upp ett ord men
uppslagsresultatet täcker helt över sidan och omöjliggör fortsatt
läsning. För att fortsätta mĺste man klicka bort uppslagsresultatet.
Pĺ min gamla dator blir ocksĺ hanteringen seg i nĺgra sekunder efter
ett uppslag. Den största fördelen med det här programmet är att
lexikonet är ganska omfattande. Det brukar ge svar även pĺ ganska
ovanliga ord.
Pĺ
http://hem.passagen.se/eramura/svenska/ordindex.htm
har Mujde Rashid lagt en svensk-kurdisk ordlista. I mappen ordlistor.zip
som ligger under rubriken Lexikoncentral pĺ http://hem2.passagen.se/lean2724)
finns denna ordlista anpassad för att kunna användas som ordlista i
LexSup. I denna version av ordlistan är kurdiska ord skrivna med
latinska bokstäver.
Nationellt centrum för sfi och svenska som andrasprĺk har en hemsida pĺ
http://www1.lhs.se/sfi/index.html
Där finns bl a lästips och länkar.
Pĺ hemsidan
http://matmin.kevius.com/index.html
har Bruno Kevius lagt en matematisk uppslagsbok.
Pĺ hemsidan
http://www.elfdalsasen.com
har Älvdalsĺsens hembygdsförening en ordlista för älvdalska.
Pĺ hemsidan
http://web.telia.com/~u97502328/
har John Josefsson lagt ut en ordlista för Meänkieli. Där finns ocksĺ ett
avsnitt ur hans bok med minnen frĺn Markitta by. Jag har använt hans
ordlista för att göra ett lexikon för Meänkieli.
Pĺ http://www.tkukoulu.fi/~cina/ finns en rysk sprĺkkurs för nybörjare.
Den använder utf8-kodning.
NYTT
====
2009-12-02 Jag har gjort en hel del ändringar i hanteringen av universaltangentbord. Fortfarande
finns en del fel kvar och jag har ännu inte gjort nĺgon bruksanvisning men jag lägger ut det som
finns i befintligt skick. Jag har även bytt ut LexSup134 i "Mĺnadens färdiga mapp".
2009-11-26 Jag har, ett par dagar i förtid, lagt ut december mĺnads färdiga mapp.
2009-11-22 Jag har gjort nĺgra ändringar i tangentbordshanteringen.
2009-11-17 Jag har gjort en del ändringar i tangentbordshanteringen. Det gĺr nu att lägga in
val av tangentbord i teck.tab och jag tänker, men har ännu inte gjort det, lägga in ett sĺdant val
i teck.tab i svkin134 sĺ att LexSup öppnar direkt med Universalbord
2009-11-16 Jag upptäckte att tangentbordet för tvĺbytestecken fungerar bra om man vill
skriva kyrilliska bokstäver med charset 204. Jag har därför döpt om det till Universalbord.
Tills vidare ligger det kvar även under namnet Tvĺbytestecken.
2009-11-14 Jag har kompletterat tangentbordet för tvĺbytestecken sĺ att man även kan
använda shift-tangenten. Det gör att man kan adressera cirka 4 000 tecken. För att se om det
fungerar har jag lagt in nĺgra provtecken i mustecken.tab i svkin134 i det kinesiska
lexikonet.
2009-11-11 Jag har börjat titta pĺ möjligheten att skriva tvĺbytestecken, till exempel kinesiska,
med tangentbordet. I artikeln om Det kinesiska brevet
finns beskrivet hur man använder detta. Jag har ocksĺ lagt till lite till mustecken.tab i
svkin134 i det kinesiska lexikonet.
009-10-22 När jag började med LexSup gällde stränga regler för vilka tecken som fick ingĺ
i filnamn. Jag började därför stuva in ord med främmande begynnelsebokstäver i filer med
godkända namn. Men detta är inte helt problemfritt. Idag kan man använda filnamn med
tecken som ligger även i fjärde nibble. Pĺ sikt kanske man borde övergĺ till lexikon med
filer för fler begynnelsebokstäver än bara latinska bokstäver, siffror och &. Men det bör ske
sĺ att även gamla lexikon förblir användbara. Jag har därför nu gjort sĺ att LexSup först
letar efter en fil med den verkliga begynnelsebokstaven (eller första delen av ett
flerbytestecken). Om inte det ger en exakt träff fortsätter sökningen enligt tidigare regler för
instuvning i filer med godkända namn. Det verkar som om detta fungerar men tala om om
det ger nĺgra problem!! När det gäller insortering, lexikonomvändning och sĺdant fungerar
detta bara delvis.
2009-10-10 Jag har rättat i hanteringen av förhandsvisning av tecken i Musskrift.
2009-10-06 Jag har rättat nĺgra fel i hanteringen av ; vid konvertering mellan 134 och
html-unicode.
Jag har ocksĺ ändrat i programmet FontMap. Det visar nu även UTF8-kod.
2009-10-05 Jag har ändrat principen för hantering av html-unicode i lexikonen. Jag tog inte
med avslutande ; som en del av teckenkoden men nu har jag ändrat sĺ att den ingĺr i
teckenkoden. Det har medfört en del ändringar i kinesiska lexikon och i procedurerna för
"Översätt".
Att ändra i stora lexikon är vanskligt. Skulle man göra nĺgot fel kan det vara mycket svĺrt
att rätta till det när man glömt vad man gjorde. En lösning pĺ det är att använda utvecklingslexikon
som man gör lista ifrĺn och sorterar in när man väl är bergfast övertygad om att de är felfria.
Men för att markera att det finns tilläggslexikon visas begynnelsebokstav även för tilläggslexikon som inte gett nĺgon träff. Om man inte vill ha denna visning kan man nu för tilläggslexikon sätta
uppslagna ordet för begynnelsebokstaven till #?#. Dĺ tas denna och föregĺende post bort.
Jag lägger med ett tomt sĺdant utvecklingslexikon i installationsmappen.
2009-09-25 Jag har lagt in en möjlighet att konvertera mellan charset 134 och html-unicode.
Visserligen gĺr det att göra sĺdan konvertering i Microsofts Word eller via Googles
översättningstjänst men jag har ändĺ tyckt att det kan vara bra att ha möjligheten i
LexSup. Proceduren finns under "Översätt" pĺ huvudmenyn. Konverteringslexikonen ligger
tillsammans med det kinesiska lexikonet. Proceduren fungerar men nĺgra tecken saknas
i lexikonen och den är lite lĺngsam. Pĺ min gamla dator tar det en stund att konvertera en
lĺng fil.
Pĺ grund av platsbrist pĺ den här sidan har jag flyttat det kinesiska lexikonet till min
ekonomisida och lagt en direktlänk dit.
2009-09-22 Jag har nu lagt in möjlighet att nĺ de 100 vanligaste kinesiska tecknen
i charset 134 via musskrift. Jag har ännu inte beskrivit hur man gör i Bruksanvisningar men
i kinesbrev.htm finns en beskrivning av möjligheten.
2009-04-02 Med Musskrift kommer man ĺt hela teckenbyten. Om man väljer ett Charset med
enbytestecken kan man även i Musskrift se vilka tecken man fĺr när man väljer dem. Men om
man är ovan vid Musskrift och om man har en mus med dĺlig precision är det lite svĺrt att
hantera teckenvalet. Jag har därför lagt in en möjlighet att välja mellan KlickMod och MoveMod.
I KlickMod klickar man pĺ det tecken man vill ha. Och nu öppnar Musskrift i KlickMod. Vill man
ha MoveMod fĺr man växla till det.
Jag har ocksĺ rättat ett fel i "Lexikon till lista" och lagt till en möjlighet att byta
första / pĺ varje rad mot @.
2009-03-27 Jag har gjort nĺgra försök med att skriva kinesiska genom att knyta tangentbordet
till kaligrafistreck. Det som finns nu är enbart till för att testa metoden. Om du vill se hur det
fungerar klickar du pĺ Options-Tangentbord-KaligrafiStreck. Jag har ocksĺ lagt till nĺgra
fĺ ord i det isländska lexikonet.
2009-03-24 Jag tänkte att jag skall se om jag kan förstĺ nĺgot pĺ isländska. Sĺ jag hämtade
de texter som Gutenberg har pĺ isländska. Isländska är märkligt eftersom det finns en
nordisk ton i det som man känner igen trots att man ingenting begriper. Sĺ jag tänkte se om
det lilla isländska lexikonet skulle kunna ge nĺgot. Men det medförde att jag upptäckte ett
problem. Gutenberg lagrar HTML-text i Utf-8-format. I den texten är enbart teckenbytens
första halva okodad. Alla tecken i teckenbytens övre halva är alltsĺ kodade och om man
konverterar till HTML-Unicode fĺr man dem i kodad form. Det är OK i en browser men i
lexikonet ligger de som enbytestecken. Jag har därför lagt in en möjlighet att hämta filtrerad fil
och omvandla kodade tecken i första byten till enbytestecken. Det visade sig att lexikonet i
nuvarande skick är alltför litet för att ge nĺgot nämnvärt bidrag till textförstĺelse.
2009-03-20 Jag har gjort en del ändringar när det gäller hämtning av filtrerad fil. Jag har
ocksĺ kompletterat det kinesiska lexikonet med nĺgra ord sĺ att det nu närmar sig 6 000
ord.
2009-03-17 För att komma ifrĺn problemet att hantera stor eller liten begynnelsebokstav
sorteras uppslagsorden för varje begynnelsebokstavsfil med början frĺn andra
bokstaven. Men detta fungerar inte för kinesiska tecken eftersom tecken med olika
inledningsbyte ligger i samma fil. Jag har nu ändrat i Insortering och i Lexikonomvändning
för att fĺ dessa att fungera även i kinesmod. Det börjar bli en hel del som hanteras
annorlunda i kinesmod vilket gör att det är viktigt att veta om LexSup stĺr i kinesmod
eller inte. Jag har därför lagt in att Inordrutans färg växlar till Fuchsia när LexSup sätts i
kinesmod. Jag har ocksĺ ändrat en del i fonthanteringen för att snabba upp hanteringen.
2009-03-16 Jag har ändrat i fonthanteringen för att kunna slĺ upp och se kinesiska
tecken. Jag har ocksĺ rättat nĺgra fel i hur Utfilrutan och Memorutan visas.
2009-03-15 Frĺn Peter Bondessons lexikonprogram (se Länkar ovan) har jag hämtat ett
isländskt, ett grekiskt och ett walesiskt lexikon som jag konverterat till LexSup-
lexikon.
2009-03-11 Ibland kan det vara lättare att skriva kinesiska med charset i stället för med
HTML-Unicode. Jag har gjort en del ändringar för att möjligöra det och kompletterat det
kinesiska lexikonet med ett lexikon för charset 134. Mer om hur man kan använda detta
finns i Det kinesiska brevet.
2009-03-07 Charset, UTF-8, HTML-Unicode, UCS-2 är bara nĺgra exempel pĺ olika sätt att
koda flerbytestecken. Och det vimlar av försök att hantera dessa pĺ ett "smart" sätt vilket
innebär att det är nästan omöjligt att veta vad som händer när man hämtar, ändrar eller
sparar en text. Jag har försökt fĺ nĺgra övergĺngar att fungera men i mĺnga fall blir
inte resultatet vad det borde bli. Testa först innan du använder nĺgon konvertering av
en fil som innehĺller väsentlig information!! Och se till att du har nĺgon back-up-fil!! Än
verkar det vara lĺngt kvar innan drömmen om att UTF-8 skall lösa alla problem blir en sanndröm.
2009-02-28 Det fanns en bug i Insortering som gjorde att det blev fel om rader i insorteringslistan
inte avslutades med mellanslag. Eftersom jag har använt insorteringslistor där raderna avlutats
med mellanslag har jag inte märkt detta förrän nu. Jag har nu försökt rätta till detta och hoppas
att det skall fungera. Men tänk pĺ att alltid ha en backup av lexikon som du ändrar i.
När det gäller kinesiska sĺ motsvaras mĺnga av vĺra vanliga ord av teckengrupper. Men det
är mĺnga gĺnger ett mysterium hur det kinesiska sprĺket kopplat samman begrepp till
teckengrupper. Frĺgan är dĺ hur "Översätt" och "Översätt ordtecken" skall visa tecken som bara
finns som första del i en teckengrupp. Visar man namnet pĺ hela teckengruppen kan det vara
helt fel. Men mĺnga gĺnger kan teckengruppens namn ge en antydan om vad inledningstecknet
stĺr för. Jag har nu gjort sĺ att teckengruppens namn visas med * som avslutning.
2009-02-27 Det kinesiska lexikonet har nu passerat 5 000 uppslagsord. Användbarhet börjar
vid 30 000 ord och dit är det en bra bit kvar. Men det är inte längre häpnadsväckande om
man finner ett ord i lexikonet. Men i kinesiska räcker det inte med en antydan om
ordbetydelse. Man mĺste skaffa sig en känsla för hur tecken och ord sätts samman för
att ge mening. Men man kan nu hämta hem kinesiska texter och börja bekanta sig med dem.
Texter finns bland annat pĺ Gutenberg (se länk under Länkar ovan). Om man hämtar en
text i UTF-8 format kan man med "Arkiv-Hämta filtrerad fil" konvertera den till HTML-Unicode
som lexikonet använder.
2009-02-26 Jag upptäckte att mĺnga vanliga ord inte motsvaras av ett kinesiskt tecken utan
av en teckengrupp. Man kan ju se en sĺdan teckengrupp som en fras men eftersom den
skrivs ihop utan mellanslag fungerar inte fraskontrollen pĺ den. Jag har därför gjort sĺ
under rubrikerna "Översätt" och "Översätt ordtecken" att en fraskontroll alltid görs om
uppslagsordet börjar med &. Under dessa rubriker är ocksĺ fraskontrollen avkortad till
100 bytes i stället för 200 bytes.
2009-02-24 Jag har rättat fel i hanteringen av tecken i Kommentarrutan. Bland annat har jag
lagt in en rensning av rutan frĺn radbörjansmarkering och en ĺterställning av ĹÄÖ. Jag har
ocksĺ ändrat ĺteruppslag med mushjulet sĺ att man rullar nedĺt bland Utordrutorna när man för
hjulet framĺt och aktiverar uppslag när man drar det tillbaka. Teckenhantering är knepig men
jag hoppas att alla ändringar skall fungera OK och att de gĺr pĺ alla datorer. Hör av dig om
du upptäcker nĺgot problem!!! QFZ-funktionen fungerar inte när Översätt lägger kommentarer
i Anmärkningsrutan.
2009-02-23 Jag har rättat en del fel i Översätt. Bland annat fungerade inte ĺteruppslag med
mushjulet pĺ rätt sätt.
2009-02-18 Jag har ändrat en del i konverteringen av Utf-8 till HTML-Unicode. Hoppas det
fungerar som det ska.
2009-02-14 Jag har gjort en del ändringar när det gäller att skriva och läsa kinesiska. Hur man
använder detta finns ännu inte beskrivet i Bruksanvisningar men jag har lagt lite om det i
kinesbrev.htm.
2009-02-12 Jag har lagt in en rubrik som heter "Översätt tecken" under "Internet". Tanken med
den är att man skall kunna se pĺ t ex kinesiska texter sĺ att man ser tecken och översättning
intill varandra. Man hämtar en text kodad i Unicode för html-text i Utfilrutan. Sĺ klickar man pĺ
"Översätt tecken" och fĺr dĺ upp Browserrutan. Utfilrutans text läggs i en fil som heter
LexSupTrans2Qvaolett.htm och Browserrutan navigerar till den. Man ser dĺ tecknen i
Browserrutan. När man klickar pĺ "Översätt nĺgra tecken" skjuts översättningen in i texten
efter tecknet. Man ser alltsĺ i Browserrutan tecknen följda av Lexikon2:s översättningsförslag.
2009-02-10 Sakta,sakta växer det kinesiska lexikonet. Det är nu uppe i c:a
400 tecken. Men för att ett lexikon skall vara intressant mĺste det finnas
texter att skriva och läsa. Under Kinesiska ovan finns nĺgra synpunkter pĺ det.
2009-01-29 Jag har utökat det spanska och det finska lexikonet och bytt ut
det lilla Interlingua-lexikonet mot det större.
2009-01-19 Jag har kompletterat det spanska lexikonet sĺ att det nu innehĺller
cirka 10 000 svenska uppslagsord.
2009-01-14 Jag har lagt in en metod att hĺlla reda pĺ vilka ord som hör samman
i Utfilruta, Översättningsruta och Anmärkningslista. Hur man gör framgĺr av
Bruksanvisningar-Översättning. Det fungerar för det mesta men kan missa om
texten innehĺller vissa specialtecken. Jag har ocksĺ stuvat om lite i det
engelsksvenska lexikonet. För att testa Översätt har jag använt stycken ur
Treasure Island (Skattkammarön) som jag hämtat pĺ http://www.gutenberg.org .
2009-01-10 Jag har lagt in en Anmärkningslista som visas när man kör "Översätt".
I den listas ord som har flera alternativ och/eller kommentarer.
2009-01-06 Jag har lagt ut ett utkast till holländskt lexikon med 800 uppslagsord.
Jag har ocksĺ stuvat om lite i engelsk-svenska lexikonet för att fĺ Översätt att
ge ett mer begripligt resultat.
2009-01-05 Jag har utökat det finska lexikonet frĺn 6 000 till 9 000 uppslagsord
och det kinesiska frĺn 50 till 200. Jag har ocksĺ ändrat en del i programmet för
att göra det möjligt att slĺ upp html-unicode.
2008-12-17 Jag har tittat lite pĺ möjligheten att göra ett utkast till lettiskt
lexikon. Men ett problem är att det lettiska alfabetet innehĺller en del tecken
som inte finns i det engelska alfabetet. Och att använda Unicode i ett program
som skall kunna slĺ upp i lexikon är inte helt enkelt. Jag trodde först att man
bara kunde göra om eventuella Unicode-tecken till baltiskt charset och skriva
och slĺ upp i lexikonen som vanligt. Men i lettiska förekommer tydligen s med
cirkumflex som saknas i baltiskt charset. Jag har i alla fall lagt till en
möjlighet att konvertera Unicode till baltiskt charset.
2008-12-10 Jag har lagt till en möjlighet att spara Översättningsrutan. Den kommer
fram under Arkiv om man har Översättningsrutan framme. Jag har ocksĺ lagt in en
möjlighet att lägga samman listor. Den finns under Lexikonhantering. Om man har
ett antal ord pĺ ett sprĺk och samma ord pĺ ett annat sprĺk kanske man vill göra
en lista där varje ord pĺ det ena sprĺket stĺr pĺ samma rad som motsvarande ord
i det andra sprĺket, det vill säga en lista som gĺr att använda för insortering.
Dĺ kan man använda Listsammanläggning som finns under Lexikonhantering. Jag
har ocksĺ kompletterat det finska lexikonet med ett par hundra ord.
2008-12-07 Jag har rättat nĺgra buggar i Översätt och lagt en länk till Googles
översättningsservice under Länkar ovan.
2008-12-01 Jag har, med stor tvekan, börjat lägga in en möjlighet att "översätta"
nĺgra rader i taget. Den här delen är inte färdig men det som hittills är klart finns
under Översätt pĺ huvudmenyn. Varje ord (eller fras) översätts med lexikonets
första alternativ. Jag provade med en engelsk text som gav rena rapakaljan.
Hittills har jag inte brytt mig om i vilken ordning alternativen har stĺtt i lexikonen.
I mĺnga fall har därför mycket udda betydelser hamnat som första alternativ.
Jag har nu gjort en del ändringar i ensv vilket resulterade i att man kanske kan
ana vad en text handlar om.
2008-10-22 Det är möjligt att Interlingua skulle kunna användas som mellansprĺk
vid tvĺstegsuppslag. För den som vill prova finns nu nĺgra Interlingua-lexikon.
2008-10-12 Jag upptäckte, the hard way, att om man har direktpar aktiverat och
klickar pĺ Arkiv-Nytt sĺ raderas hela den fil som man höll pĺ med. Jag har nu
ändrat sĺ att Arkiv-Nytt tar bort filnamnet och därigenom inaktiverar direktspar.
Jag har ocksĺ börjat se pĺ möjligheten att använda mellansprĺk och som ett första
steg lagt ut ett lexikon till Interlingua. För att fĺ plats med detta har jag flyttat det
engelska lexikonet till min ekonomisida med en direktlänk till det. Det engelska
lexikonet ligger ju i installationsprogrammet sĺ jag tror inte att behovet av att
ha det separat är särskilt stort.
2008-10-07 Jag har ändrat i exit-hanteringen. Det verkade lite fĺnigt att man fick
frĺgan om man ville spara Utfilrutan även om den var tom. Jag upptäckte ocksĺ att
sprĺkbyte kan vara katastrofalt om man har direktspar aktivarat. Sprĺkbyte lägger
ju en text i Utfilrutan och med direktspar försvinner dĺ hela den fil man arbetar med.
Jag har ändrat en del i den här hanteringen och hoppas att den fungerar bättre men
man bör nog undvika att byta sprĺk under pĺgĺende arbete.
2008-09-28 Jag brukar inte använda LexSup för att surfa pĺ nätet. Det är bara om
jag stöter pĺ irriterande redirect eller har behov av lexikonstöd som jag tar till
LexSup. Men ibland händer det att jag hittar adresser som jag vill spara för att
kunna ĺterkomma till. När man stänger LexSup försvinner hela URL-listan. Men jag
har nu lagt in en möjlighet att spara adresser och att ĺtergĺ till dem. Hur man gör
finns beskrivet i Bruksanvisningar - Internet (i slutet).
2008-09-27 Pĺ mina gamla datorer hände det ganska ofta att skriften stoppade upp
när jag skrev lĺnga html-filer med browserrutan framme. Jag har nu försökt ĺtgärda detta
sĺ att normala sparfunktioner aktiveras om inte uppdateringen hänger med.
2008-09-19 Jag har ändrat lite i frasmodshanteringen. Om den inskrivna
frasen inte finns i frasmod2 läggs det inskrivna in i Utfilrutan. Jag har ocksĺ
lagt till nĺgra kinesiska tecken.
2008-04-14 Jag har lagt in en möjlighet att sätta tangentbordet i permanent frasmod.
Jag har även i OrdFras2.tab börjat lägga in nĺgra koder som jag ofta använder när
jag skriver html-text.
2008-04-13 Jag har ändrat sĺ att Utfilrutan fĺr focus när man öppnar LexSup även
om inte muspekaren stĺr pĺ Utfilrutan. Jag har ocksĺ lagt in ytterligare en möjlighet
att sätta tangentbordet i frasmod (frasmod2). Mer om detta under Tangentbord
och Kinesiska ovan.
2008-04-11 Se Tangentbord ovan.
2008-04-08 Jag har lagt in en möjlighet att lägga in en egen teckenuppsättning
för tangentbordet ( se Tangentbord ovan).
2008-04-05 Jag har rättat nĺgra fel i fonterna LexSupCyr1.ttf och LexSupGrek1.ttf
som ligger i installationsprogrammet.
2008-04-03 Jag har lagt ett tangnetbord med grekiska tecken. Jag tänkte
bara lägga bokstäverna med grekisk placering men lĺta alla övriga
tangenter vara oförändrade. Tyvärr finns det en del fel i LexSupGrek1.ttf
som aktiveras när man väljer det grekiska tangentbordet. För tillfället har
jag inte möjlighet att rätta varken detta eller felen i LexSupCyr1.ttf. Tecknen
kommer rätt i browsern.
2008-04-01 Jag har lagt in en möjlighet att ställa om tangentbordet sĺ att
det ger tecken pĺ liknande sätt som ett ryskt tangentbord (Options-
Tangentbord). Ett par tangenter har jag behĺllit pĺ samma plats som
pĺ det svenska tangentbordet. Och ett par tecken (Ё och Щ)
blir lite speciella. Щ hamnar pĺ ´-tangenten vilket innebär att man
fĺr trycka pĺ tangenten tvĺ gĺnger sĺ att man fĺr tvĺ tecken där man tar
bort det ena. Ё saknas t v i LexSupCyr1.ttf men den kommer rätt i
en browser kodad för Windows-kyrilliska tecken. Den skrivs med
tangenten längst till höger i näst översta raden följd av E eller e.
2008-03-29 Jag har gjort nĺgra ändringar i hanteringen av utf-8.
2008-03-28 Jag upptäckte att jag glömt att lägga till avslutande ; pĺ
HTML-unicoden vid konvertering frĺn Utf-8.
2008-03-27 Vissa HTML-texter är kodade enligt utf-8. Utfilrutan i LexSup är
en RichEdit-ruta som inte klarar att hantera utf-8 pĺ rätt sätt. Det medför
att alla sparprocedurer inkl Direktspar förstör utf-8-filer. Jag har nu gjort sĺ att
när du hämtar filer med filnamnstillägget .htm eller .html kontrolleras om de första
2000 bytes innehĺller strängen utf-8. I sĺ fall fĺr du en panel där du kan välja om
du vill ladda in filen som den är eller konvertera den till HTML-unicode. Om du
konverterar den och vill behĺlla originalfilen kan du spara den som oformaterad
fil under ett nytt namn. Tills vidare fungerar konverteringen bara för tvĺ-bytes-tecken.
2008-03-25 Jag har ändrat en del i unicode-hanteringen. I RichEdit finns tvĺ
sätt att ange unicode-tecken. Antingen med \u..? eller genom att i filhuvudet
lägga in en font med charset och sedan anropa denna font för skrivna tecken.
Hur dessa möjligheter fungerar när man hämtar och sparar formaterade eller
oformaterade filer är en hel vetenskap. Jag borde nog skriva lite om det men
det har jag ännu inte gjort.
2008-03-20 Det var ett tag sedan jag använde det ryska lexikonet. När jag nu
skulle använda det enligt beskrivningen i "Ryska posten" upptäckte jag att
uppslag i Lexikon1 inte fungerade. Jag har i nĺgot sammanhang ändrat i
valet av begynnelsebokstav sĺ att det inte fungerar med latinska bokstäver
när man har valt "Främmande Latinskt till Special". Jag har nu ändrat sĺ att
begynnelsebokstaven bara ändras om den ligger i teckenbytens övre
halva och om man inte kastat om sprĺk med dubbelkomma. Det finns ocksĺ
en del problem med ĹÄÖ och med uppslag i det rysk-svenska lexikonet för
vissa begynnelsebokstäver. Jag hade tänkt lösa detta genom att använda
siffror som begynnelsbokstäver. Detta är bara delvis genomfört men jag har
gjort en del ändringar i den riktningen.
Omvandling av rtf-unicode fungerar bara delvis. Sĺ snart man börjar rota i
rtf-formateringen fĺr man de mest otänkbara resultat.
2008-03-18 Jag har rättat nĺgra fel och lagt ut en mapp med lĺngsamma
bokstavsljud till Lära läsa.
2008-03-16 En vacker dag kanske unicodehanteringen fungerar som den skall.
2008-03-15 En del blev fel i hanteringen av unicode. Jag har ocksĺ tänkt om
när det gäller förskjutningsvärde. I stället för att justera in tecknet i
teckenbyten och sedan förskjuta det har jag nu använt totala förskjutningsvärden
och för &# - kodning endast omvandlat om värdet faller inom övre nibble av
teckenbyten. Det gör att man kan ha unicodetecken för t ex matematiska
symboler som förblir opĺverkade om man t ex omvandlar kyrilliska tecken.
Jag har ocksĺ gjort nĺgra ändringar i FontMap som du kan hämta under
rubriken Hämta ovan. Där kan du i Unicoderutan fĺ tecken
som gĺr att kopiera med ctrl-c och klistra in Utfilrutan. Där finns ocksĺ html-koden
för tecknet. Jag har ocksĺ lagt till ett par knappar för att bläddra i Unicoderutan.
2008-03-14 Jag har lagt begynnelsebokstäverna Š och š pĺ S och ändrat en del
pĺ omvandlingen mellan enbytestecken och unicode för html.
2008-03-11 Jag har lagt ut ett lexikon pĺ Meänkieli (Tornedalsfinska). I
Meänkieli används bokstäverna Š och š. Jag har ännu inte rättat till
hanteringen av begynnelsebokstav för att hantera detta. LexSup kan
alltsĺ hänga sig vid dessa bokstäver. Jag ĺterkommer om detta.
2008-03-01 Jag har börjat ta bort nyordshanteringen.
2008-02-15 Jag har rättat nĺgra fel i programmet och jag funderar pĺ att ta bort
nyordshanteringen. Om det kommer in fel i ett lexikon är de nästan omöjliga att
hitta. För att kunna gĺ tillbaka och kontrollera ändringar i lexikon lade jag in
nyordsmarkering sĺ att man kunde hitta nya ord och granska dem om nĺgot verkade
vara fel. Men med möjligheten att använda kompletteringslexikon fick man en
möjlighet att lägga nya ord i ett utvecklingslexikon tills man blev övertygad
om att det var OK att lägga in dem. Jag tror att det är ett bättre sätt att
hantera ändringar. Jag funderar ocksĺ pĺ att ta bort Lexikonaddition. Man kan
i stället göra en ordlista av det lexikon man vill addera och köra Insortering av
denna. En fördel med detta är att det är enklare att granska en ordlista än ett
lexikon.
2008-02-08 Jag har lagt ut en övningstext för Lära läsa.
2008-02-06 Barn som lär sig läsa skulle kanske kunna använda Spelled speech.
Jag har provat att lägga in en Lära-läsa-mod baserad pĺ Spelled speech. Frĺn
Kurts hurts (se LÄNKAR) hämtade jag Kattresan och tänkte använda den som
övningstext. Men med alla ljudfiler och bildfiler blev redan de tvĺ första verserna
för stora för den här hemsidan. Men moden finns nu inlagd och i bruksanvisningen
för Spelled speech finns beskrivet hur man använder den. Jag fĺr fundera mera
pĺ hur jag gör med övningstext.
2008-02-02 Ett problem har varit att Utfilrutan tappar focus när man har scrollat i
Browserrutan. Jag har lagt en smal remsa i Browserrutans överkant som ger
ett extra focusbyte när man för muspekaren frĺn Browserrutan till Utfilrutan. Det
tycks fungera.
2008-01-27 Jag har lagt in en möjlighet att sortera in en ordlista i Stavningsordlistan
(Lexikonhantering-Insortering i Stavningsordlista). Jag har ännu inte hunnit testa
denna möjlighet ordentligt. Använd den med försiktighet och se till att ha back-up.
Jag har ocksĺ via ordlistor och script i Kurts hurts gjort en engelsk stavningsordlista.
För att använda denna hämtar du den, döper om mappen Stavning i den mapp
där du installerade LexSup, lägger in den hämtade mappen i den mapp där du
installerade LexSup och döper om den till Stavning.
2008-01-23 Jag har rättat till scrollningen för "Spelled speech", "Sök i Utfilruta"
"Byt ut i Utfilruta" och "Sök stavfel".
2008-01-21 Jag har börjat göra en stavningskontroll. Ĺterkommer med mer
om detta men delvis fungerar det och en ordlista ligger nu med i installations-
programmet.
2008-01-16 Jag upptäckte att det inte gick att byta fil med "Hämta Utfil" om
man hade droppat en fil pĺ ikonen. Det visade sig bero pĺ att "Hämta Utfil"
anropade en startprocedur. Jag minns inte varför jag lagt in detta anrop men
jag har nu tagit bort det. Hoppas det fungerar.
2008-01-10 Jag har lagt in en möjlighet att visa bildserier även i lexikon
(se bruksanvisning). Jag upptäckte ocksĺ att mappen med olika sprĺk
för labels mm fallit bort ur installationsprogrammet sĺ jag har lagt tillbaks
den. Jag har även lagt in nĺgra ord i utkastet till uppslagslexikon.
2007-12-27 Jag har gjort en fontkarta som jag kallar FontMap. Den finns
under rubriken "HÄMTA" ovan. Frĺn början hade jag tänkt att lägga in den
som en del i LexSup men den blev sĺ lĺng sĺ jag tror att det är bättre att
ha den som ett separat program. Det gör det ocksĺ enklare att ha den igĺng
samtidigt som man arbetar med ett annat program.
2007-12-22 Jag har svĺrt att lära mig genus för tyska substantiv sĺ jag
provade med att ange genus med färgkodade utordrutor men vid närmare
eftertanke kom jag till att det npg är bättre att lägga in orden i bestämd form
sĺ att man kanslĺ upp dem eller använda "Visa lexikon" för att se genus.
För att prova detta har jag ändrat filen Aalt.lex i svensk-tyska (svty) lexikonet.
En del saknas för att jag inte direkt fann nĺgon tillförlitlig uppgift om genus
men man kan se hur det är tänkt.
2007-12-16 Jag har ändrat lite när det gäller färgkodade Utordrutor. Man
skulle kunna använda färgkod för att ange ordklass, genus, böjningsform
mm. Men för att ĺteruppslag skall fungera mĺste man dĺ ta bort färgkoden
frĺn Utordrutans text. Det har jag nu gjort. Jag har ocksĺ lagt in en möjlighet
att ange färg med en siffra vilket innebär att alla färger blir tillgängliga (utom
färgvärdet 1 som används för att ange att en bokstav används som färgkod).
För mörka färger syns texten dĺligt och jag har därför lagt in en koll av
bakgrundsfärg som ställer om textens färg till vitt om bakgrunden är mörk.
Det här kan ge problem med att Delfi inte är helt pĺlitligt när det gäller
fontfärger men det lilla jag har hunnit kolla sĺ verkar det fungera. Jag har
funderat pĺ att lägga in färger för ordklasser o dyl men det borde göras
efter ett genomtänkt system sĺ att man kan lära sig vad färgerna betyder
och där har jag inget bra förslag. Hör gärna av dig om det!!
2007-12-05 Älvdalska är ett sprĺk (eller en dialekt) som talas i Älvdalen i
norra Dalarna. Sprĺket är intressant bl a för att det bevarat en del av den
äldre svenskan. Älvdalsĺsens hembygdsförening har pĺ sin hemsida
http://www.elfdalsasen.com
en ordlista som jag använt för att göra ett LexSup-lexikon.
2007-11-15 Jag har lagt in en möjlighet att sortera ordlistor o dyl
(Options-Sortering).
2007-11-03 Jag upptäckte ett fel i programmet som gjorde att Browserrutan
pĺ vissa datorer visades förskjuten till höger. Det gjorde att jag fann att det
kan finnas tillfällen när man vill kunna se Utfilrutans vänsterkant under
Browserrutan. Jag har därför lagt Browserrutans vänsterkant 10 pixels frĺn
skärmkanten sĺ att man kan lägga Utfilrutans Textyta med mindre vänster-
marginal sĺ att dess kant syns. Jag har ocksĺ ändrat i LexSup1.ini sĺ att
LexSup efter installationen startar med vänstermarginalen 6 pixels.
2007-10-30 Möjligheten att skriva i Utfilrutan och direkt uppdatera en
Utfil som visas i Browserrutan ger en möjlighet att hantera andra alfabet.
I Bruksanvisningar-Internet (bara i den version som ligger i installa-
tionsprogrammet) har jag beskrivit hur man kan använda detta.
2007-10-22 Det har varit problem med Sök och Byt under Redigera. Ett
av problemen har varit att dessa använder textmarkering som i LexSup
används även för andra ändamĺl. Jag har nu ändrat sĺ att dessa
möjligheter fungerar om än inte exakt pĺ samma sätt som i alla andra
program. Hur de fungerar finns beskrivet i Bruksanvisning. Jag har bara
ändrat i programmet i installationsmappen.
2007-10-18 Jag har rättat (hoppas jag) nĺgra buggar i Textkontroll.
2007-10-11 Jag har provat att lägga in teckensprĺksbilder.
2007-10-10 Jag har lagt ut ett utkast till Uppslagslexikon, tagit bort
en visa och en klockfil ur Litteraturmappen och gjort nĺgra smĺändingar
programmet.
2007-10-07 Jag har lagt in en möjlighet att infoga uppslagsordet i
en internetadress och en möjlighet att i lexikon lägga en mapp som
heter web och i den lägga en fil som heter web.txt och som innehĺller
generella internetadresser som visas vid varje uppslag.
2007-10-03 Möjligheten att ha Utfilrutan tillgänglig samtidigt som
browserrutan visade sig öppna en intressant möjlighet att redigera
html-text. Om man öppnar en html-text i Utfilrutan och via Internet-
Browse och Sök öppnar den Browser-rutan kan man skriva i Utfil-rutan
och direkt se i Browserrutan hur det blir. Om Browserrutan visas, om
den är nedsänkt och om dess URL är samma som Utfilrutans filnamn
skriver Utfilrutan direkt till Utfilen som visas i Browserrutan. Pĺ min
gamla dator är detta en operation som inte gĺr blixtsnabbt och man
fĺr därför inte skriva alltför snabbt. Av nĺgon anledning missar ocksĺ
focus-valet sĺ att man kan fĺ höja och sänka browserrutan för att fĺ
focus att hamna pĺ Utfilrutan. Eftersom texten skrivs direkt till Utfilen
är procedurerna för att spara fil avaktiverade i detta läge.
2007-10-03 Jag upptäckte att det kan vara praktiskt att ha tillgĺng
till Utfilrutan utan att behöva stänga browsern. Jag har därför lagt
in en knapp som heter Sänk (bredvid Stäng browser) som sänker
browserrutan sĺ att Utfilrutan blir tillgänglig.
2007-10-02 Jag har lagt in en möjlighet att färgkoda utordrutorna.
Detta är tänkt för kommande speciallexikon som t ex biologiskt
artlexikon. Ett första utkast till ett biologiskt artlexikon finns
som skofza-lexikon under rubriken Lexikon ovan. För att fĺ plats
med det har jag plockat bort en del ur Litteraturmappen.
2007-09-29 Frĺn Peter Bondessons norska ordlista har jag gjort ett
norskt lexikon. Där finns en del ord som jag undrar över men det fĺr
ligga tills vidare. Hör av dig om du hittar nĺgot konstigt i det.
Jag har lagt in en möjlighet att lĺta browsern söka efter
länkar till lexikonmappen i stället för att söka pĺ Internet. Om man
lägger en länk där första tecknet är > i stället för < söker LexSup
i lexikonmappen efter en fil med det namn som finns inom citationstecken
i länken. Ett exempel pĺ detta finns pĺ uppslagsordet Fermat i
matematiklexikonet.
2007-09-27 Jag har lagt ut ett lexikon som slĺr upp i Bruno Kevius
matematiska uppslagsverk matmin. LexSup är petigt när det gäller
bokstavordning och det kan förekomma en del fel där ett felplacerat
ord skymmer följande ord. Men jag lägger ut det i det skick det
nu befinner sig för att rätta fel när jag hittar dem.
2007-09-26 Jag har rättat (hoppas jag) nĺgra smĺfel i programmet.
2007-09-24 Jag har lagt in en möjlighet att använda internetlänkar som
uppslagna ord i lexikon. En sĺdan länk visas som vanligt i en Utordruta.
Om den har < som första tecken tolkas den som en länk när man aktiverar
den. Den första del av texten som stĺr inom " " används dĺ som URL och
LexSup öppnar browsern.
2007-09-19 Jag tänker lägga om lexikonen. I stället för att lägga ett
flertal lexikon i installationsprogrammet tänker jag lägga alla lexikon
som separata lexikon som man kan lyfta in i den mapp där man installerat
programmet. Fördelen med det är att man slipper fĺ med lexikon som man
inte är intresserad av och att man lätt kommer ĺt lexikonen om man vill
hämta dem för nĺgot annat än att använda dem ihop med LexSup.
2007-07-23 Det finns ett problem med kommentarer i tilläggslexikon. För
huvudlexikonet visas kommentarer till det uppslagsord som LexSup finner
men vad skall visas för tilläggslexikon om detta uppslagsord avviker frĺn
inordet? Jag har nu ändrat sĺ att kommentarer frĺn tilläggslexikon hör till
inordet och bara visas om detta finns i kommentarfilen.
2007-07-22 Jag har börjat lägga in en möjlighet att använda utvecklings-
lexikon. Att utbyta stora lexikon, t ex via Internet, innebär en del problem.
Det är nästan omöjligt att granska ett lexikon pĺ mĺnga tusen ord.
Om det innehĺller fel och man lägger samman det med ett annat stort lexikon
gĺr det sedan inte att hitta och rätta felen. Det kan därför vara bättre att
utbyta kompletteringar i form av tilläggslexikon pĺ nĺgot hundratal ord
som man kan granska och provanvända tills man är övertygad om att det
är lämpligt och ofarligt att lägga samman tilläggslexikonet med huvud-
lexikonet. Jag har ännu inte hunnit provanvända denna möjlighet men jag
lägger ändĺ ut den och hoppas att den inte innehĺller alltför mĺnga
buggar.
2007-05-28 Frĺn Mujde Rashids ordlista har jag gjort ett kurdiskt
LexSup-lexikon som ligger med i installationsprogrammet (mapparna
svkul och kulsv). I detta är kurdiska ord skrivna med latinska bokstäver.
2007-05-26 Jag har i mappen ordlistor.zip pĺ http://hem2.passagen.se/lean2724)
lagt en kurdisk ordlista som gjorts av Mujde Rashid.
2007-05-22 Jag har lagt in en möjlighet att lägga info-filer i lexikonmappar och i
LexSup:s startmapp. Det gör att man kan lägga in information om ett lexikon
och/eller reklam o dyl.
Jag har ocksĺ kompletterat browsern med en möjlighet att surfa bakĺt.
2007-04-20 Jag har lagt in en möjlighet att lägga in kommentarer via
Insortering. Det är lite bristfälligt provat men det tycks fungera.
2007-04-16 Jag har lagt in en länk till tyda.se.
2007-04-05 Det har blivit enklare (inte mycket men nĺgot) att slĺ upp
ord frĺn browsern.
2007-03-24 Jag har lagt WordGumbos holländsk-engelska ordlista
i zip-filen med ordlistor och flyttat den filen till passagensidan.
2007-03-23 Jag har lagt till en möjlighet att använda midi-filer
i Spelled speech.
2007-03-15 Jag har rättat ett fel i hanteringen av teckengrupper i
spelled speech och gjort en del ändringar enligt Melodier ovan.
2007-03-14 Se Melodier ovan.
2007-03-11 Jag har ibland saknat möjligheter att i LexSup blanda olika
fonter i samma dokument. Det har bl a handlat om att skriva rubriker o dyl.
Och att skilja ut avsnitt med annan färg eller med kursiv text. I början
tyckte jag inte det spelade nĺgon roll. Det finns ju andra program som
klarar detta och det var inte för detta som jag skrev LexSup. Men nu har
jag ändĺ lagt in Tecken som en rubrik pĺ huvudmenyn som gör att man i
Utfilrutan kan ändra font inne i ett dokument och spara det som rtf-fil.
Pĺ mina gamla datorer fungerar det inte alltid. Vissa varianter pĺ
fonter gĺr inte. Egentligen hade jag tänkt försöka använda det för att
välja charset för inkommande tecken och kanske kunna slippa använda
memoruta men det fungerar inte pĺ mina datorer sĺ jag behĺller memorutan
tills vidare.
2007-03-10 Ännu sĺ länge stuvar jag om hejdlöst i kinesiska lexikonet och
i de delar av LexSup som hanterar det. Hoppas det inte skadar nĺgot annat.
Jag har flyttat det som lĺg i 1alt.lex till 2alt.lex. Det är nog sĺ att
man fĺr göra olika lexikon för olika charsets sĺ jag kallar det här för
kinsv136 för att visa att det är gjort för charset 136.
2007-03-08 Jag har gjort en del ändringar för att göra det möjligt att
skriva och läsa kinesiska. Hoppas att det inte har förstört nĺgot annat.
Ännu ĺterstĺr mycket. Jag lägger med ett kinesiskt-svenskt lexikon (kinsv).
Jag har hittills bara hittat 5 ord som jag tror att jag vet vad de betyder.
Det kan ju verka lite meningslöst att lägga ut ett lexikon med bara 5 ord
men det visar hur jag har tänkt fortsätta. Anm: För att Inordrutan skall
kunna ta emot kinesiska tecken mĺste man byta till charset 136 i Startvärden.
2007-03-06 Se KINESISKA ovan.
2007-03-01 Jag har lagt in en möjlighet att med hjälp av # som radslut
hĺlla samman texter i ordlistor och ordböcker.
2007-02-17 Jag har ändrat lite i browserns adresshantering.
2007-02-16 Jag har rättat nĺgra smĺfel i programmet.
2007-02-07 Jag upptäckte att under resans gĺng har en del ord fallit bort
ur de engelska lexikonen. Jag har med "Lexikon till lista" gjort om gamla
lexikon till listor och kört dessa med "Nya listord" mot dagens lexikon.
Resultatet av detta har jag via "Insortering" lagt in i lexikonen.
Även det svensk-finska lexikonet visade sig behöva samma behandling och
det finsk-svenska tycks ha drabbats av en total katastrof. Jag har nu gjort
ett nytt finsk-svenskt lexikon.
2007-02-06 Jag har börjat göra ett utkast till en svensk-lettisk ordlista.
2007-02-04 Jag har ĺtergĺtt till att göra ändringar i den version som
ligger i installationsprogrammet pĺ denna sida.
Det förekommer en del olika sätt att hantera icke-latinska alfabet. I
t ex WordGumbos ryska ordlistor används en metod att med tags ange
Unicode-värde för varje bokstav och dessutom ange transkription till
latinsk motsvarighet. Det blir lĺnga filer som blir helt ohanterliga
när det gäller att slĺ upp i dem. Jag har därför modifierat "Options-
Unicode till enbytestecken" sĺ att man kan omvandla dem till listor
med kyrilliska bokstäver enligt LexSupCyr1. Men de innehĺller en del
radskift och det blir en del rester av tags kvar som man mĺste hantera
manuellt för att kunna använda dem som ordlistor för LexSup.
2007-02-01 Jag har lagt in LexSup med browser i installationsprogrammet
och flyttat det gamla installationsprogrammet till
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
Jag har ännu inte gĺtt igenom alla lexikon för att kontrollera alla
ords placering efter att jag ändrat uppslagsfunktionens sätt att hantera
bokstavsordning. Det kan alltsĺ finnas felplacerade ord i lexikonen.
Jag har även gĺtt igenom lite mer av ordboken men den nya versionen
ryms inte pĺ den här sidan sĺ även den ligger pĺ lean2724.
2007-01-31 Jag har gjort en del ändringar i LexSupInt med syfte att
komma fram till en standard för vad som är bokstavsordning för stora,
smĺ och ovanliga bokstäver.
2007-01-29 Jag har gjort en del ändringar i LexSupInt.
2007-01-25 Hantering av begynnelsebokstav är inte helt enkel när
man har stora och smĺ bokstäver och när man behöver använda bokstäver
utöver dem som ingĺr i engelska alfabetet. Jag har börjat försöka fĺ
ordning pĺ detta men jag lägger bara in ändringar i versionen med
browser (LexSupInt) som finns pĺ
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
2007-01-20 Jag har provat att lägga in en browser i LexSup. Tanken
är att man skall kunna surfa med lexikonstöd. Programmet är lĺngt
ifrĺn färdigt och jag har haft en del problem med browsern pĺ vissa
datorer. Jag lägger därför detta program i en särskilt zip-fil pĺ
http://hem2.passagen.se/lean2724
(Klicka pĺ Lexikoncentral pĺ Menyn).
2007-01-18 Pĺ Internet förekommer ofta ordlistor i tabellform. I
Bruksanvisningen för Musskrift har jag beskrivit hur man kan kopiera
sĺdana till ordlsitor som gĺr att använda i LexSup.
2007-01-16 Jag har gjort nĺgra smĺändringar och lagt till en början till
ett polskt lexikon. Konverteringsprogrammet i extralex.zip kan nu
konvertera ryska skriven med ljudmotsvarande latinska bokstäver till
kyrillisk text enligt LexSupCyr1. Denna konvertering är emellertid
inte helt fullständig och den kan ge en del fel men den fungerar
hjälpligt för WordGumbos ryska listor.
2007-01-08 Jag har gjort en del ändringar för att förbättra tvĺstegs-
uppslag. Den här typen av ändringar är riskabla. Risken är stor att
de ger oväntade problem men en del tycks i alla fall fungera som förut.
Frĺn WordGumbos ordlistor har jag gjort ett isländskt och ett polskt
lexikon som man kan använda tillsammans med ett engelskt lexikon för
tvĺstegsuppslag. Polska använder en del skrivtecken som saknas i
västerländska enbytes-fonter. Man använder därför Charset 238 för
polska. Jag kan ingen polska och kan därför inte se hur WordGumbo har
hanterat detta, jag har bara gjort som det stĺr i deras listor.
2007-01-06 Jag har gjort ett konverteringsprogram för att omvandla
bl a ordlistor frĺn WordGumbo till insorteringslistor för LexSup (se
Om mellansprĺk). Jag har även ändrat en del pĺ
hanteringen av begynnelsebokstav och rättat ett fel i Musskrift.
2007-01-04 Se Om mellansprĺk ovan.
2006-12-30 Jag har gjort lite ändringar av bildhanteringen för att kunna
lägga in bilder i ordboken.
2006-12-27 Jag har nu gĺtt igenom ordboken. Den vimlar av gamla socialister
som jag aldrig hört talas om och det finns nog en hel del fel i den. Dels
finns det inscanningsfel och dels har nog sprĺkbruket ändrats en del
sedan 1927. Pĺ nĺgra stället har jag gjort smärre ändringar men i stort
sett följer den den inscannade versionen. Jag tänkte undan för undan
komplettera med nytt material. Att den innehĺller en del förlegat material
är ju egentligen inte nĺgot fel. För den som söker gammal information
är den kanske en guldgruva.
2006-12-19 Jag har gjort nĺgra kompletteringar pĺ engelska lexikonen.
2006-12-17 Jag har sorterat in en svensk ordlista frĺn wordgumbo i
det engelska lexikonet. Det nya lexikonet ligger i installationsprogrammet.
2006-12-16 Jag har lagt in nĺgra intressanta länkar under rubriken
LÄNKAR.
2006-12-15 Jag har lagt in lite mer av ordboken.
2006-12-14 Jag har lagt in en möjlighet att ändra lexikon till
ordlistor. Förut gick detta att göra genom att göra en lexikon-
omvändning som samtidigt gav en ordlista enligt utgĺngslexikonet.
Men jag behövde göra en del listor utan att ha nĺgot behov av
lexikonomvändning och när jag gjorde listor frĺn mycket smĺ
lexikon blev begynnelsebokstav och filslut en stor del av listorna.
Detta gäller fortfarande för listor som görs vid lexikonomvändning
men den nya proceduren rensar bort dessa delar av en lista.
Jag har ocksĺ lagt in ett danskt lexikon. Hur det är med kvaliten
beror pĺ kvaliten hos de källor jag använt och den är jag osäker
om. Hoppas att det är nĺgorlunda tillförlitligt.
2006-12-09 Jag har lagt ut början pĺ en ordbok. Se under rubriken
Ordbok ovan.
2006-11-21 Jag har nu hittat ett sätt att hantera ĺteruppslag frĺn
Lexikon2 som förefaller fungera bĺde under Windows98 och WindowsXP och
även vid uppslag av delar av ord.
2006-11-20a Det visar sig att Windows98 och WindowsXP hanterar ändringar
av markerad text lite olika. Vid ĺteruppslag frĺn Lexikon2 mĺste man
ta bort textmarkeringen sĺ att inte det markerade ordet raderas. I
Windows98, men inte i WindowsXP raderas dĺ texten i utordrutorna sĺ att
det inte finns nĺgot att slĺ upp i Lexikon1. Jag har nu ändrat för att
avhjälpa detta men den nya placeringen av cursorn blir olika sĺ att
sista bokstaven i det markerade ordet raderas i Windows98. Jag ĺterkommer
om denna bug.
2006-11-20 När man kör Lexikonomvändning fĺr man en omvändning av
lexikonets glosdel. Vad som menas med omvändningen av kommentardelen
är däremot oklart. Jag vill ju hela tiden ha kommentarerna pĺ mitt
modersmĺl. Men om man gör en omvändning för att fĺ ett lexikon för
andra med annat modersmĺl borde man ju göra helt nya kommentarer. Sĺ
kommentardelen följer inte med till det nya lexikonet. Men ibland skulle
man vilja komma ĺt kommentarerna när man har det omvända lexikonet som
Lexikon2. Ett sätt att göra det kan vara att använda ĺteruppslag även
för Lexikon2. Jag har därför lagt in möjlighet att även vid uppslag i
Lexikon2 bläddra med 4 och 0 samt att välja alternativ för ĺteruppslag
i Lexikon1 med 1 , 2 eller 3. Pĺ det sättet kommer man alltsĺ ĺt
kommentarerna i Lexikon1.
2006-11-18 Alltid finns det nĺgot att ändra. Jag har gjort nĺgra ändringar
av musskrift.
2006-11-16 Jag har rättat nĺgra smĺfel. Den Memo-ruta som täcker över
utfilrutan när man använder musskrift och ett charset>10 har fĺtt en
lite annan bakgrundsfärg än den vanliga utfilrutan. När man använder
ett charset som är ganska likt det vanliga alfabetet, t ex 238 för
sprĺk som polska, kan det vara svĺrt att veta om man ser Memo-rutan
eller den vanliga Utfilrutan. Med lite olika färg pĺ dem gĺr det att
se vilken som är framme. Vid utskrift försvinner Memo-rutans bakgrundsfärg
för att skrivaren skall slippa skriva ut den. Färgen ĺterkommer när
utskriften avslutas.
2006-11-15 Jag har gjort lite förbättringar (hoppas jag) pĺ musskrift och
ändrat lite i spelled speech.
2006-11-06 Jag la egentligen in Musskrift som ett sätt att i nödfall
kunna komma ĺt tecken som är svĺra att nĺ via tangentbordet, t ex
japanska och kinesiska tvĺ-bytes-tecken. För att det inte skulle, mer
än nödvändigt, inkräkta pĺ annat gjorde jag rutorna sĺ smĺ som möjligt.
Men det betyder att man mĺste använda en mus med hög precision. Med
min gamla mus som galopperar över skärmen är det nästan omöjligt att
skriva med denna musskrift. Jag har därför lagt in en möjlighet att
expandera musskriften till dubbla storleken.
2006-10-30 Jag har lagt ut en svensk-dansk ordlista.
2006-10-27
Jag har ändrat lite pĺ hanteringen av första bokstaven i uppslags-
ordet. Jag hoppas det skall fungera bättre utan att ställa till
med oväntade problem. Jag har ocksĺ rättat ett fel i hanteringen
av "Flera Alternativ" när man använder tilläggslexikon.
2006-10-25 Jag har flyttat sammanslagna lexikon för engelska och
finska frĺn nyalex.zip till installationsprogrammet. Mina gamla
lexikon för engelska och finska är därmed borttagna.
Jag har ändrat lite pĺ hanteringen av reservrader i etikettfilerna.
Det gör att de gamla mapparna Lang1 och Lang2 inte längre fungerar.
Använd dem som nu finns i installationsprogrammet.
2006-10-23
Jag har börjat göra det möjligt att välja sprĺk för etiketter och
bruksanvisningar. Än sĺ länge fungerar det bara för nĺgra fĺ etiketter
och jag har ännu inte översatt nĺgra bruksanvisningar men man kan se
hur det är tänkt. Jag har tagit bort mappen Anvisningar. De filer
som lĺg där finns nu i mappen Lang\Lang1. Jag har ocksĺ ändrat lite
pĺ hanteringen av Inordruta, Uppslagsord och Utordrutor för att göra
det möjligt att komma ĺt text som inte ryms i rutan. Hur detta är
gjort finns i Bruksanvisning under rubriken Fraser.
2006-10-21
Om man vill provanvända ett lexikon eller tillfälligt ha tillgĺng
till ett speciallexikon kunde det vara lämpligt att kunna lägga till
ett tilläggslexikon till det vanliga lexikonet. Det är nu möjligt att
lägga in sĺdana tilläggslexikon. Under Bruksanvisningar-Lexikonhantering
finns beskrivet hur man gör. Jag hoppas att detta inte stör andra
funktioner men man bör nog undvika att göra ändringar i lexikon
via LexSups ändringsfunktioner sĺ länge man har tilläggslexikon
inlagda.
2006-10-17
I nĺgra fall släckte jag utordrutor utan att tömma dem. Det
medförde att gamla utord kunde dyka upp under fel uppslagsord
t ex vid insortering. Jag har nu försökt rätta detta.
2006-10-14
Jag har nu tagit bort "lexsupfiler". Och jag har gjort nĺgra
ändringar i hanteringen av ordlistor och lagt ut nĺgra ordlistor
som jag hittat pĺ nätet och modifierat för att passa för LexSup.
2006-10-12
Jag har gjort nĺgra ändringar i hanteringen av ordlistor och
hoppas att det fungerar utan att ställa till nĺgra problem med
andra delar av programmet.
2006-10-11
Det verkar som om installationsprogrammet fungerar och den version
som ligger i "lexsupfiler" börjar bli förlegad sĺ jag tänker ta
bort den.
Jag har kompletterat anvisningarna för ordlistor.
2006-10-10
Jag har lagt in en möjlighet att ersätta Lexikon1 med en ordlista
med godtyckligt format. Enda kravet pĺ ordlistan är att det är en
radindelad textfil. Vid uppslag i en sĺdan ordlista söks listan
igenom efter uppslagsordet och de rader som innehĺller det visas
i kommentarrutan.
2006-10-08
När man vill titta pĺ en fil med Hackerbild är man ofta bara
intresserad av ett litet avsnitt. Kanske vill man se filhuvudet
eller ett par rader för att se hur en text är formaterad. Det
är ju dĺ onödigt att ga igenom hela filen. Jag har därför gjort
sĺ att Hackerbilden öppnar med 20 16-bytes rader. Vill du se mer
fĺr du ändra i rutorna för frĺn och till.
Jag har flyttat "Sök i Utfilrutan" frĺn Options till Redigera.
Jag tänkte ocksĺ lägga in en möjlighet att byta ut strängar i
Utfilrutan men det är nĺgot fel med ReplaceDialog i min Delphi
sĺ jag har stängt av den funktionen.
Jag har även gjort en del smĺändringar som jag hoppas är
förbättringar.
2006-10-05
Jag har lagt samman Peter Bondessons svensk-finska lexikon med
mitt gamla. Resultatet finns i mappen med nya lexikon. Där finns
även ett swahili-svenskt lexikon som är gjort genom lexikon-
omvändning.
2006-10-01
Ibland händer det att man tar in en fil i Utfilrutan och fĺr ett
oväntat resultat. Man frĺgar sig dĺ vad det egentligen stĺr i
filen. För nĺgra ĺr sedan vimlade det av hackerprogram som man
kunde använda för att syna en fil närmare men när jag nu letar
efter nĺgot sĺdant hittar jag ingenting och det bästa vore ju
om jag direkt i LexSup kunde granska filen. Sĺ jag har under
Arkiv pĺ huvudmenyn lagt in en möjlighet att visa en fil i
en hackerbild. Inläggningen strulade en hel del men jag hoppas
att resten av programmet fungerar som vanligt. Under Windows 98
kan man bara titta pĺ korta filer.
Peter Bondesson har pĺ sin hemsida
http://web.telia.com/~u85724740
lagt ett lexikonprogram och ett antal ĺtkomliga lexikon. Lexikonen
äri de flesta fall betydligt bättre än mina och de skulle ganska
lätt kunna anpassas för att fungera under LexSup. Jag ĺterkommer
om detta.
2006-09-24
Det är skillnad mellan hur Windows 98 och Windows XP hanterar
filnamn. I Windows XP fungerar inte Delphi-funktionen FileExists
för filnamn som innehĺller html-tag. Jag har ändrat hanteringen
för att fĺ spelled speech att fungera även för tags under XP. Jag
har ocksĺ försökt fĺ läsningen att inte haka upp sig vid ny rad
som följs av mellanslag. Fortfarande hänger läsningen sig vid
ny rad följd av mellanslag och tag men det är kanske sĺ ovanligt
att det är acceptabelt.
Jag funderar pĺ att ta bort sudoku-hanteraren för att fĺ mer
plats för annat.
2006-09-21 em
De fonter som fanns i mappen med fonter finns nu i den font-mapp
som ligger i installationsprogrammet. Jag har därför permanent
tagit bort mappen med fonter.
2006-09-21
Jag har ändrat lite i paushanteringen och jag har lagt till
hantering av nĺgra specialtecken i spelled speech. Men ljudfiler
är skrymmande och jag har tills vidare fĺtt lov att ta bort
mappen med fonter eftersom jag annars överskrider utrymmet pĺ
denna hemsida.
2006-09-20
Bokstavsljuden för t , p och k gav obehaglig överstyrning av
ljudenheten. Jag har nu dragit ner dem lite. Och jag har lagt
till ande och ing som exempel pĺ stavelseljud.
2006-09-17
Jag har nu lagt in möjlighet att i mappen för bokstavsljud lägga
filer med flerbokstavsljud. Det gĺr alltsĺ att lägga in sje-ljud
i en fil som heter sj.wav och det gĺr att lägga in stavelseljud.
Programmet letar nu ocksĺ i lexikonfilerna efter en ljudfil som
motsvarar vad som stĺr i editrutan. Finns det en sĺdan läses den
i stället för bokstav-för-bokstavs-läsning.
2006-09-15
Jag börjar nu fĺ lite ordning pĺ spelled speech och lägger därför in
det i installationsprogrammet. Det innebär att jag kan lägga tillbaka
demon, fonter och sudokuhanteraren.
2006-09-14
Jag har gjort försök med spelled speech.
Spelled speech diskuteras ibland som ett hjälpmedel för blinda men man
brukar avfärda det med att det är varken skrift eller tal. Men det är
ju egentligen inte nĺgot argument. Spelled speech är spelled speech och
kan användas av dem som finner det användbart.
Inläggningen av spelled speech har ännu en del buggar och jag är osäker
pĺ hur man bör göra en del saker sĺ jag lägger bara ut det kompilerade
programmet tillsammans med en mapp med bokstavsljud. Du kan hämta det
genom att klicka pĺ
spelledsp.zip Borttaget! Ingĺr nu i installationsprogrammet.
För att fĺ plats med detta pĺ hemsidan har jag tagit bort den demo som
lĺg här (med ett föredrag om energi). Denna demo har jag lagt pĺ min
huvudsida och under rubriken HÄMTA ovan finns en länk dit. Jag har ocksĺ
flyttat zip-filen med fonter till huvudsidan och länken under HÄMTA gĺr
alltsĺ dit. Det visade sig att detta inte räckte sĺ jag har även flyttat
sudokuhanteraren till min huvudsida och länkat dit.
Bokstavsljuden finns i en mapp som heter spsp. LexSup letar efter denna
i mappen för lexikon 1, mappen för lexikon 2, öppningsmappen och i utfil-
mappen. För att LexSup skall hitta den mĺste du alltsĺ lägga den pĺ nĺgot
av dessa ställen.
Bokstavsljuden är ännu sĺ länge bedrövliga men med Windows Ljudinspelare
kan du göra egna och bättre bokstavsljud.
När du klickar pĺ Spelled speech pĺ huvudmenyn öppnas en panel med en
editruta och tvĺ knappar (Nästa och Stäng). LexSup startar vid cursorn
i Utfilrutan och lägger in bokstäverna fram till nästa mellanslag i
editrutan. Och därpĺ läser LexSup texten i editrutan med spelled speech.
När du klickar pĺ Nästa läggs nästa ord in och läses.
Du kan skriva i editrutan. När du skriver en bokstav läser LexSup den.
om du avslutar texten med ett mellanslag läser LexSup hela texten i
editrutan (p g a en bug dubbelläses sista bokstaven). Om du avslutar
med ytterligare ett mellanslag läggs texten i editrutan in vid cursorn
i Utfilrutan.
Om du klickar pĺ ramen runt editrutan läggs det som stĺr i editrutan
in som uppslagsord och LexSup hämtar översättningsförslag frĺn Lexikon 1
och lägger in upp till tre förslag i editrutan varpĺ dessa läses med
spelled speech.
Under pĺgĺende läsning blockeras alla andra funktioner och om du t ex
klickar pĺ nĺgot händer ingenting förrän läsningen är klar.
2006-06-09
Windows vimlar av "smarta" lösningar som med nästan osviklig intuition
ger fel resultat. När det gäller fonter är väl avsikten att om en font
eller ett visst tecken saknas sĺ skall Windows automatiskt hitta bästa
tillgängliga alternativ. Men det innebär att resultatet kan bli nästan
vad som helst. Jag har gjort nĺgra försök att skriva devanagari och
japanska tecken vilket fungerar nĺgot sĺ när pĺ min version av Windows XP
men inte alls under Windows 98. Jag lägger i alla fall programmet i
befintligt skick i installationsprogrammet och lĺter det ligga där över
sommaren.
Intressant information om japanska finns pĺ
http://www.japanska.se
Om du där slĺr upp ett ord i ordlistan och sedan klickar pĺ tecknet fĺr
du nĺgot som kallas Kanjiuppslagning som ger en hel del information om
tecknet.
2006-06-05
Jag har börjat skissa pĺ ett sätt att hantera japanska och kinesiska
skrivtecken med hjälp av Musskrift. Hur man använder det som hittills
är klart framgĺr av bruksanvisningen för LexSups Musskrift. Det är bara
den version som ingĺr i installationsprogrammet som har denna möjlighet.
2006-06-01
Jag har kompletterat och rättat musskrift. Den nya versionen ligger i
installationsprogrammet men ej lexsupfiler.
2006-05-20
En fördel med Musskrift är att man nĺr fler tecken än med tangentbordet.
Speciellt när man behöver hantera flera alfabet eller alfabet med mĺnga
tecken kan detta vara en viktig fördel. Jag tänkte därför lägga in
en förenklad version av Musskrift i LexSup. Denna är ännu inte färdig
och än mindre avlusad men jag lägger ändĺ in det som nu finns i den
version som ingĺr i installationsprogrammet.
Vid uppslag i lexikon försvinner musskriftfältet och ersätts av en
blĺ ruta mellan Utordrutorna och Kommentarrutan. Klicka pĺ denna för
att ĺterställa musskriftfältet.
2006-05-18
Ännu ĺterstĺr mycket innan LexSup kan hantera Devanagari men det fĺr
bli en uppgift för mörka höstkvällar. Jag lägger i alla fall ut det
som nu finns. Det har medför en hel del ändringar och det finns
risk att nĺgot annat skadats. Jag har ocksĺ utgĺtt frĺn att fonten
xdvng.ttf finns installerad. Jag har därför lagt in xdvng.ttf i
installationsprogrammet sĺ att den installeras. Men jag har inte
ändrat de filer som ligger i lexsupfiler. Skulle den version som
ligger i installationsprogrammet inte fungera finns alltsĺ den
föregĺende versionen i lexsupfiler.
xdvng.ttf innehĺller sĺ mĺnga tecken att det inte finns utrymme att
samtidigt ha ett latinskt alfabet inom en byte. För att kunna slĺ i
ett lexikon mellan ett sprĺk som använder latinskt alfabet och ett som
använder Devanagari mĺste man alltsĺ växla font. Microsoft har i
Windows lagt in "smarta" sätt att automatiskt välja bästa font. Ibland
fungerar detta bra men när man vill styra valet av font ger det ofta
oväntade och oöbskade resultat. Programmet är skrivet i Delphi6 och
provat pĺ en dator med en ganska gammal version av Windows XP Professional.
Du kan välja xdvng som font och fĺr dĺ Utfilrutan i Devanagari. Du kan där
skriva text genom att skriva de tecken som motsvarar Devanagari-tecknen i
xdvng. Eftersom denna font har fler tecken än vad tangentbordet direkt kan
adressera mĺste du använda tangentbordsförskjutning för att nĺ vissa tecken.
Detta är naturligtvis möjligt men knappast praktiskt användbart. Här krävs
en bättre lösning!
Om du vill slĺ upp ett ord med dubbelkomma skriver du tvĺ kommatecken och dĺ
gĺr Utfilrutan och Inordrutan över i latinskt alfabet medan Utordrutorna gĺr
över i Devanagari. När du väljer ett ord eller skriver SPACE gĺr Utfilrutan
tillbaka till Devanagari.
xdvng använder ett charset som heter SYMBOL. Delphi6 klarar inte hantering av
markerad text i detta charset. Om du markerar ett ord i texten gĺr därför
Utfilrutan över till latinskt alfabet innan ordet slĺs upp i Lexikon2. Du
ĺtergĺr genom att klicka pĺ nĺgon Utordruta eller genom att föra mushjulet
framĺt. Det här ger ett problem när du vill dubbelklicka pĺ ett ord i
stället för att markera det. Vid första klicket gĺr Utfilrutan över till
latinskt alfabet och eftersom tecknen inte tar samma utrymme som tidigare
hamnar inte cursorn under muspekaren. Du fĺr alltsĺ klicka, flytta muspekaren
till cursorn och dubbelklicka.
I princip skulle det nu gĺ att börja göra ett lexikon frĺn ett sprĺk med
latinska bokstäver till t ex Hindi. Ett omvänt lexikon däremot kräver en del
ändringar när det gäller hantering av begynnelsebokstäver.
GLAD SOMMAR!!!
2006-05-16
DEVANAGARI
Sanskrit,Hindi och en del andra indiska sprĺk använder en teckengrupp
som heter Devanagari. Man kan som i det latinska alfabetet ha ett tecken
för varje sprĺkljud eller som i kinesiska och japanska alfabetet ett
tecken för varje ord. Sprĺkljudstecken blir sĺ fĺ att ett par alfabet
ryms inom en byte. Ordtecken blir sĺ mĺnga att det är helt uteslutet
att försöka rymma dem inom en byte. Devanagari är ett mellanting som
kan kallas ett stavelsealfabet.
Pĺ adressen
http://sanskrit.gde.to/hindi/dict
finns engelsk-hindi-lexikon. Där används en font som heter xdvng.ttf för
hindi-texten. Jag har hämtat den gratis och utgĺr frĺn att den inte
är copyright-skyddad sĺ jag lägger med den i installationsfilen för
LexSup. Du hittar den i den mapp där du packar upp LexSup. Men jag
har inte lagt in den sĺ att den installeras vid uppackningen. Vill du
ha den mĺste du själv installera den i Windows.
xdvng.ttf använder ett charset som heter SYMBOL. Av nĺgon anledning
lyckas inte LexSup ställa om till detta charset när jag kör det under
min version av Windows XP (men under Windows 98 fungerar det). Jag
har därför lagt in ett par rader i källkoden som ställer om charset
för fontnamnet xdvng vilket medför att det fungerar under XP.
xdvng använder sĺ stor del av byten att det latinska alfabetet inte
ryms. Byter du font till xdvng byts alltsĺ alla tecken till Devanagari.
Som det nu är fungerar alltsĺ inte lexikonprincipen med ord pĺ tvĺ
sprĺk.
2006-05-10
Jag har lagt in en ĺteruppslagsfunktion.
LexSup använder tvĺ lexikon. När man slĺr upp ett ord i ett av dessa
fĺr man ett eller flera alternativ. Jag har nu gjort sĺ att när men
väljer ett av dessa slĺs det valda alternativet upp i det andra lexikonet.
Det här kan vara ett sätt att undvika en del misstag och det öppnar en
möjlighet till tvĺstegslexikon.
Antag att du vill läsa en text pĺ hindi och lyckas hitta ett användbart
lexikon för hindi-engelska. Dĺ kan du lägga detta som Lexikon2 och ensv
som Lexikon1. Om du markerar ett ord i texten slĺs det upp i Lexikon2 och
om du väljer ett av de alternativ du fĺr upp i Utordrutorna slĺs det upp
i ensv till svenska. I slutet pĺ Bruksanvisning finns beskrivet hur detta
fungerar.
2006-04-16
Om man vill lägga in mer omfattande kommentarer och/eller
kommentarer som innehĺller matematiska symboler, index, exponenter
och sĺdant fungerar inte den vanliga kommentarrutan. Jag har
därför lagt in en möjlighet att använda helfilskommentarer. Hur
man gör finns beskrivet i Bruksanvisning.
Jag har lagt in nĺgra enstaka ord pĺ swahili. Det är tydligen sĺ
att swahili använder förleder i stället för ändelser för att skilja
mellan olika böjningsformer. Det kan ju innebära ett problem när
maa slĺr upp ord efter begynnelsebokstav. Om man tar med alla
böjningsformer bör det ju fungera men man borde nog veta lite mer om
det här än vad jag gör.
2006-04-13
Pĺ min tekniksida
http://web.telia.com/~u87701228
har jag lagt en text om begreppen "Här och Nu". Du hittar den under
"NYTT" pĺ menyn.
Den ligger som en .zip-fil tillsammans med LexSup och visar hur jag
tänkt mig att man kan skicka filer tillsammans med LexSup.
För att se hur filhuvud och alla tags ser ut kan du hämta nu.rtf med "Arkiv -
Hämta oformaterad utfil".
2006-04-09
Under rubriken Litteratur har jag lagt en länk till projekt Runeberg.
2006-04-07
Jag har kompletterat rtf-mallen genom att i filhuvudet lägga in fonten
Arial som är en font där anrop av tecken som ligger utanför den första
byten sker med backslash-u-siffra-? . Det kan vara bra att ha med en
sĺdan font om man t ex vill komma ĺt matematiska symboler. Vilka siffror
som ger vad hittar du i filen för html-tecken.
Det visade sig att Windows XP och Windows 98 hanterar richtext pĺ lite
olika sätt. Jag har använt Windows XP men de anrop av tecken och charsets
som jag har använt fungerar inte under Windows 98. Problemet är väl av
övergĺende art eftersom användningen av Windows 98 troligen minskar när
det blir allt mer omodernt. Jag tror inte det är mödan värt att försöka
göra nĺgot ĺt det.
2006-04-04
Jag har börjat se lite pĺ användning av olika charsets och andra
formateringsmöjligheter. Det kräver nog en hel del ytterligare eftertanke
men nĺgra synpunkter finns i "Om textformatering" under "Bruksanvisningar".
I den mapp där du installerar LexSup finns ocksĺ en rtf-mall som du
kan använda för att se hur man kan använda charsets.
2006-03-29
I en äldre version (LexSup1) fanns en möjlighet att skriva in och aktivera
tags i en text, t ex för att skriva index och exponenter. Denna möjlighet
orsakade en del problem sĺ jag tog bort den. Ett annat sätt att hantera
tags är att lägga in dem i en fil med oformaterad text som läses som
richtext. För att underlätta detta har jag ändrat hanteringen av text-
formatering. Det gĺr nu att under Arkiv hämta och spara oformaterad text.
Jag har ocksĺ under Bruksanvisningar lagt in lite om textformatering och
tags.
2006-03-20
Jag har gjort en demo för att visa hur man kan lägga ihop en text med
bilder och lexikon. Den gĺr att hämta genom att klicka pĺ
Demo1 1,1 MB
Det är ett föredrag som jag höll vid SET 2006-03-16. Packa upp det, kör
lexsup.exe och klicka pĺ de röda figurmarkeringarna för att se figurerna.
Som vanligt när man försöker använda nĺgot upptäcker man en del problem
och uppläggningen av demon har lett till att jag ändrat en del i hanteringen
av ini-filer.
2006-03-19
Jag har lagt till möjligheten att även använda jpg-bilder.
När man gjorde insortering frĺn lista hände det ibland att programmet
slog upp och lade till nĺgra ord ur nĺgot nyligen använt lexikon. För att
komma ifrĺn detta har jag ändrat sĺ att insorteringen sätter det
reulterande lexikonet som aktuellt lexikon. Hoppas det fungerar.
2006-03-12
Jag har ändrat procedurer för att ta bort radslut och tags och jag har
lagt till en möjlighet (Options - lägg in radslut) att lägga in radslut.
Dessa nya procedurer arbetar enbart med texten i Utfilrutan och
pĺverkar inga diskfiler förrän du sparar resultatet.
Ibland vill man ändra bredden pĺ en text med fasta radslut. Det gĺr
nu att använda LexSup för det. Ta in texten i Utfilrutan, ta bort
radsluten, ändra textrutans bredd och lägg in radslut. Ev kan du
behöva göra en del manuella komletteringar.
Jag har lagt till nĺgra uppslagsord i början av t i svfin och jag har
ändrat filsluten i det lexikonet.
2006-03-04
Jag har nu tagit bort LexSupK. Jag har även tagit bort Nya lexikon och
Lexikon eftersom de senaste varianterna av lexikonen ingĺr i installations-
programmet. Det börjar bli lite trĺngt pĺ hemsidan och det är onödigt att
dubbellägga information.
Jag har börjat skissa lite pĺ ett lexikon pĺ Swahili och hittat lite
mellan engelska och swahili som jag utgĺr frĺn. Det har medfört att jag
använt Insortering, Lexikonaddition och Lexikonomvändning och hittat en del
fel i dessa procedurer. Bl a nyordsmarkerade Lexikonaddition även
upplslagsord vilket gjorde att man mĺste ta bort nyordsmarkeringarna innan
LexSup kunde hitta dem. Och filsluten är ett stort problem. Det är helt
otroligt hur mĺnga varianter det kan bli beroende pĺ hur filer avslutas.
Jag har nu gjort sĺ att Varje fil skall avslutas med
.a˙˙˙ .b˙˙˙
Filavslutning Filavslutning ......
och vid Lexikonaddition, Insortering eller Lexikonomvändning överförs inte
filsluten frĺn ingĺende filer om inte dessa enbart kopieras. I stället
avslutas filer med standardavslut. Av befintliga lexikon har jag rättat
sven och lagt in rätt filslut. De övriga kommer jag att rätta sĺ snart
jag fĺr tid till det.
Ett problem var ocksĺ att programmet hängde sig om kommentarfiler saknades.
Jag har nu ändrat detta sĺ att det tycks fungera.
För att underlätta uppläggning av nya lexikon har jag även lagt med ett
tomt lexikon. Och för att visa hur man kan lägga upp en lista för insortering
har jag lagt med min första lista för swahili (lista1.txt). För att hitta
svenska ord att utgĺ frĺn när man börjar pĺ ett nytt lexikon har jag
använt en lista över de tusen vanligaste orden i romaner. Den innehöll
en hel del egennamn och böjningsformer. Jag har försökt sortera bort dem
och gjort en lista som ligger med som svenskord.txt.
2006-02-21em
Jag har rättat nĺgra smĺfel i Bruksanvisningen och lagt in den nya versionen
i lexsup.zip (men inte i lexsupfiler.zip). Jag funderar pĺ att rensa bort en del frĺn
den här sidan. LexSupK skrevs vid en tid dĺ det förekom att man skickade
filer via disketter pĺ 1.44 MB. Det var dĺ viktigt att hĺlla nere storleken pĺ
programmet. Men det här är nog inte nĺgot problem idag. Pĺ en CD kan man
ju lika gärna lägga LexSup. Det finns därför ingen anledning att LexSupK tar
upp plats här pĺ sidan. Likasĺ är lexikon som jag uppdaterat och lagt in i
LexSup inte aktuella i särskilda mappar.
2006-02-21
Jag har ändrat i LexSup för att det skall gĺ att lägga programmet
pĺ en CD och köra det därifrĺn. Jag har även lagt in en möjlighet
lägga en ini-fil tillsammans med en textfil sĺ att ini-filen körs när
man hämtar textfilen (ini-filen skall ligga i samma mapp som
textfilen och heta lexsup.ini).
2006-02-16
Jag har även lagt in en möjlighet att i ljudfilen lägga textfiler med
länkar till filer som läggs in i den i Windows inbyggda mediaspelaren.
När du skriver en sĺdan länk mĺste du även ta med filnamnstillägget.
Det ger en möjlighet att ta med alla typer av filer som mediaspelaren
kan hantera det vill säga även videoklipp av typen .mpg. Du kan
lägga en fullständig adress som länk men problemet med det är
att den förmodligen inte fungerar pĺ nĺgon annan dator än din
egen. LexSup letar därför även i ljudmappen som hör till Lexikon2
och Utfilen efter en fil med det namn du angett som länk. Det här
möjliggör illustration av begrepp med längre ljud- eller video-
sekvenser. Exempel hittar du i ref.rtf.
2006-02-15
Jag har kompletterat LexSup med möjlighet att i Ljudmappen
även lägga uppslagbara filer av typen .mid , .cda och .mp3.
Det har väl ingen nämnvärd användning för lexikonstöd men det
var ganska lätt att lägga in och jag hoppas att det inte
förstörde nĺgot annat. För att prova hur det och bildvisningen
fungerar kan du använda en text som jag lagt in under
Litteratur. Ladda ner Texter 2,3 MB och
hämta filen ref.rtf som ligger i mappen ref som i sin tur
ligger i mappen Leif Andersson.
2006-02-14
Jag har gjort en del ändringar i LexSup och kompletterat det svensk-finska
lexikonet. Ändringarna i LexSup beskriver jag i Bruksanvisingen pĺ följande
sätt:
Bildvisning
========
LexSup kan visa bilder knutna till uppslagsord i Lexikon2.
.
Lägg en mapp i mappen för Lexikon2 och döp den till "bild".
För varje uppslagsord frĺn Lexikon2 letar LexSup i denna
mapp efter en bild som heter uppslagsordet följt av ".bmp".
Om det finns en sĺdan fil visas bilden upptill till höger pĺ
skärmen. Om du klickar pĺ bilden förstoras den och om du
dubbelklickar pĺ den förstorade bilden ĺtergĺr den till litet
format. Du kan ta bort bilden med Options - Dölj bild. Om
du klickar där ändras texten till Visa bild och bilder visas
bara i en sekund för att därefter försvinna. Du kan även
ta bort bilden genom att klicka pĺ kommentarrutan. Om
bilden är stor och skymmer kommentarrutan dubbel-
klickar du pĺ den sĺ att den blir liten sĺ att du kommer
ĺt kommentarrutan.
.
Det finns även möjlighet att lägga in en serie bilder som
visas i 0,2 sekunder vardera. Du sätter dĺ en nolla framför
namnet pĺ första bilden, en etta framför nästa bildnamn
och sĺ vidare. Du kan ha upp till en nia framför bildnamnet.
.
Smĺ bilder har formatet 180x120 och stora 600x400. Det
därför lämpligt att avpassa bilder sĺ att de passar till detta
format. Bilderna mĺste vara bitmapbilder.
.
Bildvisning kan även användas för att lägga in bilder i en
text. Det mest eleganta är naturligtvis att, som i Word eller
pdf lägga in bilder inbäddade i text men det fungerar inte
pĺ enkla textfiler. LexSup erbjuder en annan möjlighet. Man
kan i samma mapp som textfilen ligger lägga en mapp som
heter bild och i denna lägga in bilder som LexSup kan
hämta genom att man klickar pĺ ord som motsvarar
bildernas filnamn. För dessa bilder gäller samma regler
som för bilder i lexikon.
.
LexSup letar först efter bild i lexikonet och därefter
i den mapp där Utfilen finns. En bild i Utfilmappen har
alltsĺ prioritet framför en bild i lexikonet.
.
Ljud
===
Pĺ liknande sätt som LexSup hanterar bilder kan du
lägga in ljudfiler knutna till uppslagsord i Lexikon2. Du kan
alltsĺ ange uttal med hjälp av ljudfiler.
.
I mappen för Lexikon2 lägger du en mapp och döper den
till "ljud". För varje uppslagsord frĺn Lexikon2 letar LexSup
i denna mapp efter en ljudfil som heter uppslagsordet följt
av ".wav". Om det finns en sĺdan fil sänds den till
ljudkortet via mediaspelaren. Ljudfiler skall vara i wav-format.
.
Genom att lägga en mapp som heter ljud i samma mapp som
Utfilen kan du lägga in ljud i en text pĺ liknande sätt som du
lägger in bilder.
.
Fraser
=====
.
Det som i ett sprĺk anges med ett ord kan i ett annat sprĺk
anges med en fras. Det är alltsĺ viktigt att kunna ha med
fraser i ett lexikon. När det gäller uppslagna ord är problemet
bara att en fras kan vara längre än vad som ryms i Utordrutan.
Men om den ryms inom kommentarrutan kan man dĺ se den
genom att klicka pĺ "Visa Lexikon".
.
När man läser en text och markerar ord för att öppna Lexikon2
kan man markera flera ord för att se om de finns som fras. Om
man markerar ett ord genom att dubbelklicka pĺ det söker
LexSup bara efter det ordet men om det följs av en fras
(= ett uppslagsord som innehĺller mellanslag) blir ramen kring
Utordrutorna gul vilket signalerar att man bör klicka pĺ
"Visa Lexikon" för att se vilken fras som ligger efter ordet.
.
När man använder dubbelkomma öppnas Lexikon1 sĺ snart
man avslutar ett ord. Men om ordet följs av en fras i Lexikon1
blir ramen runt Utordrutorna gul och man kan hitta frasen
genom att klicka pĺ "Visa Lexikon"
2006-02-02
Jag har lagt in en möjlighet att visa bilder i LexSup. Tanken var frĺn början
att prova möjligheten att göra ett universal lexikon till bilder i stället för
översättningsord. Men det är en enorm uppgift och det finns nog närmare liggande
användning för bildvisning.
Om man vill göra en uppslagsbok behöver man kunna lägga in bilder. Bilder gör
ocksĺ att man kan ĺstadkomma ABC-böcker för barn som skall lära sig att läsa
och för vuxna som skall lära sig läsa pĺ ett nytt sprĺk. Man kan lägga upp
övningstexter med klickbara ord som ger bilder. Man kan t ex använda annan
färg pĺ klickbara ord. Det gĺr inte att skriva text med annan färg i LexSup
men du kan ta in en textfil i WordPad och ändra färg pĺ ord. Du markerar dĺ
det ord du vill ha i annan färg och klickar pĺ symbolen efter F K U i
WordPad:s huvud. Du fĺr dĺ möjlighet att välja färg. Spara sĺ filen i
.rtf-format sĺ kan du använda den i LexSup.
Bilder knyts till uppslagsord i Lexikon2. För att visa hur det fungerar
har jag i engelsk-svenska lexikonet (ensv) lagt in bilder pĺ uppslagsorden
run och table. För att se hur det fungerar laddar du ner LexSup, installerar
det, skriver run och dubbelklickar pĺ det eller table och dubbelklickar pĺ
det. Hoppas det fungerar som det ska.
Jag har ocksĺ lagt in en mapp som heter Anvisningar där jag lagt de bruks-
anvisningar som ingĺr i LexSup. Tanken är att de skall vara ĺtkomliga för
utskrift o dyl.
2006-01-28
Jag har försökt rätta en del fel i LexSup när det gäller lexikonhantering.
Det finns mĺnga möjligheter till programkrasch pĺ grund av olika fel i
lexikon och när man ändrar för att lösa ett problem finns alltid risken att
nĺgot annat krĺnglar. Tala om om du hittar nĺgot fel!!!
Jag har lagt in en procedur för att räkna antal ord i lexikon. Den gör även
en kontroll av att inte lexikonet innehĺller tomrader. Denna procedur finns
under "Lexikonhantering" - "Räkna ord i Lexikon1".
Det svensk-finska lexikonet har jag kompletterat med en del uppslagsord
som börjar pĺ s. Där har jag ocksĺ försökt lägga in kommentarer pĺ det
sätt som jag har tänkt mig i ett komplett lexikon. Detta nya svensk-finska
lexikon och dess omvändning har jag lagt in i installationsprogrammet.
2006-01-08
Jag har rättat nĺgra fel i LexSup och hoppas att det inte gett nĺgra nya fel.
Rensa nyord fungerade inte för uppslagsord pĺ Ĺ, Ä, och Ö beroende pĺ
skrivfel i källkoden. Ett försök att lägga in kompletteringar av kommentarer
medförde att programmet hängde sig när det inte hittade kommentarfil eller
när det försökte lägga in kommentarer efter sista uppslagsordet. För att
komma ifrĺn problem med filslut avslutar jag filerna med ett uppslagsord
som bestĺr av begynnelsebokstaven följd av ööö. Det fungerar inte för
främmande alfabet som gĺr förbi ö men det fĺr duga tills vidare.
Jag har, med hjälp av Lexikonomvändning gjort ett finsk-svenskt lexikon och
lagt in aktuella lexikon i installationsprogrammet. De lexikon som ligger i mappen
"nyalexikon" är alltsĺ inaktuella men mappen fĺr ligga kvar tills det blir dags att
ändra den.
2005-12-29
Jag har gjort ett utkast till ett svensk-finskt lexikon. Jag började med att utgĺ
frĺn det svensk-ryska lexikonet vilket samtidigt gav mig tillfälle att rätta en del
fel i detta. Men arbetet gick lĺngsamt och för att komma igenom övergick jag till
att bara ta ord ur en uppställning över de 1000 vanligaste orden i romaner. En
hel del av dessa är böjningsformer och namn sĺ det är betydligt mindre än 1000
ord och lexikonet blev glest för de bokstäver där jag använde detta. För X, Z , W,
Ĺ, Ä och Ö har jag inte lagt in nĺgot alls. Det har alltsĺ en hel del brister men det
är en början för den som vill skapa sig ett eget lexikon. I det svensk-ryska har
jag bara rättat för de begynnelsebokstäver där jag utgick frĺn detta lexikon.
Sĺväl det svensk-finska som det rättade svensk-ryska lexikonet finns i mappen
Mappen Nya lexikon är borttagen eftersom den blivit inaktuell
Pĺ min huvudsida,
http://web.telia.com/~u87703726
under rubriken "Böcker" har jag lagt det som är klart av "Hur fiungerar din värld?"
och "Världen - Ägarens handbok":
2005-10-22
Jag har kompletterat svensk-engelska lexikonet genom att köra "Textkontroll"
(finns under Lexikonhantering) pĺ "Hur fungerar din värld?". Det gav en
del nytt men mycket ĺterstĺr ännu. Och det visade en del problem med
hantering av böjningsformer, namn, ordsammansättningar mm. Men jag lägger ut
det som jag gjorde i den nya mappen
Mappen Nya lexikon är borttagen eftersom den blivit inaktuell
Där finns ocksĺ ett försök att komplettera det svensk-tyska lexikonet. Här
finns fler problem. Bl a frĺgan om hantering av tyskt y och om stor eller
liten begynnelsebokstav för substantiv. Som det nu är finns det inte nĺgon
enhetlig linje i dessa frĺgor.
OBS!! I dessa lexikon ligger nyordsmarkeringarna kvar. Om du vill använda
dem för att göra lexikonomvändning eller lexikonaddition mĺste du först
rensa bort nyordsmarkeringarna. Det kan du göra med "Rensa nyord" som finns
under Lexikonhantering.
2005-10-02
Jag har lagt ut det som hittills är klart av bokutkastet "Hur fungerar din
värld?". Det finns under
Texter 2,3 MB
i mappen Leif Andersson. Tyvärr är jag ännu inte klar med figurerna.
Jag har ocksĺ ändrat lite pĺ hur LexSup öppnar dokument med filnamnstilläggen
.rtf och .trs.
2005-09-14
Jag har gjort försök med att lägga in ljudfiler för att kunna ange uttal.
Detta fungerar pĺ följande sätt: Om du markerar eller dubbelklickar pĺ ett
ord letar programmet efter det i Lexikon2. Om det hittar ordet visar det
översättning och ev kommentarer. Därefter letar det i den mapp som
innehĺller Lexikon2 efter en mapp som heter ljud och i denna letar det efter
en fil med ett namn som bestĺr av det markerade ordet med filnamnstillägget
.wav. Finns det en sĺdan fil startar ljudspelaren och spelar upp filen. Därvid
dyker det upp tvĺ knappar längst upp till höger pĺ skärmen. En med grön pil
som används för att upprepa uttalet och en med en röd rektangel som
används för att ĺterställa ljudspelaren sĺ att man kan upprepa uttalet.
Ljudfiler tar stor plats och det är knappast realistiskt att försöka sprida
uttalsfiler via en hemsida. Tanken är att sĺ smĺningom distribuera dem via
CD eller DVD och att göra det möjligt för den som sĺ vill att själv lägga in
uttalsexempel. Ett exempel pĺ användning kan vara följande:
Antag att du undervisar i Svenska för invandrare och har elever med engelska
som modersmĺl. Eleverna kommer dĺ att använda ett engelsk-svenskt lexikon
(ensv) som Lexikon1 och ett svensk-engelskt lexikon (sven) som Lexikon2. När
de i en svensk text dubbelklickar eller markerar ett ord söker dĺ programmet
i Lexikon2 efter en uttalsfil. Genom att spela in ett antal ord och lägga in
dessa i en mapp som heter ljud i den mapp som innehĺller Lexikon2 kan du
dĺ ĺstadkomma att de fĺr fram uttal för de ord som du anser att de kan
behöva hjälp med. Du kan pĺ detta sätt ĺstadkomma lexikon som är anpassade
till de texter som ni använder som övningstexter.
I den version som jag nu lägger ut ingĺr denna möjlighet och i lexikonmappen
sven finns en mapp som heter ljud där det finns nĺgra ord. Ljudkvaliten pĺ
dessa är dĺlig och det är bara nĺgra enstaka ord men tanken med dem är
att visa hur denna möjlighet kan användas.
Denna version innehĺller även de ändringar som jag gjorde i LexSupNy. Jag har
därför tagit bort LexSupNy. Jag hoppas att detta skall fungera men det
finns alltid en risk att ändringar ger oväntade problem, t ex att ett anrop av
ljudspelaren inte fungerar pĺ din dator. Skulle du rĺka ut för det är jag
tacksam om du hör av dig.
2005-06-08
Jag har lagt till en möjlighet att köra en teck.tab-fil i samband med att man
byter font. Och sĺ har jag rättat till nĺgra fel i förhoppning om att det inte
skapat nĺgra nya.
2005-06-07
Jag har gjort nĺgra ändringar av LexSup. Hantering av fonter för specialalfabet
är ett problem. Jag hade lagt in i själva programkoden hantering av kyrilliskt,
grekiskt och arabiskt alfabet. Men när jag började titta pĺ runor, pĺ alfabet
för hindi och sanskrit, pĺ alfabet för samiska och t o m för alfabet för spanska
inser jag att det inte gĺr att lägga en sĺdan hantering i programkoden. Man mĺste
finna nĺgon metod att hantera olika fonter pĺ annat sätt.
Jag har nu provat att använda en fil som heter teck.tab som jag lägger i
lexikonet för sprĺk som kräver speciell font. LexSup kontrollerar dĺ om det i
Lexikon1 finns en fil som heter teck.tab. Gör det det läser LexSup in den och
aktiverar det specialalfabet som finns angivet där. I lexikonet svry finns en
sĺdan fil där du kan se hur den är gjord.
Jag har ocksĺ lagt in en möjlighet att ändra höjden pĺ textytan pĺ skärmen.
Sĺdana här ändringar är alltid riskabla. Jag har gjort nĺgra tester med det
ändrade programmet men det finns risk att det krĺnglar i nĺgra avseenden. Bl a
ligger rester av den gamla hanteringen kvar. Hör av dig om du stöter pĺ nĺgot
som krĺnglar. Men under sommaren kan det vara problem att nĺ mig sĺ jag lĺter
den gamla versionen ligga kvar tills vidare. För att ladda ner den nya
versionen klickar du pĺ
(Jag har tagit bort LexSupNy. Se texten ovan)
Runor 2005-04-07
----------------
Jag har gjort en font för att skriva med runor i LexSup. Du kan
ladda ner den med
LexSupRun1.ttf
eller med hela fontpaketet
(Fontmappen borttagen. De fonter som ingick finns i installationsprogrammet)
Jag har utgĺtt frĺn tre varianter av runor.
Urnordiska runor
Stungna kortkvistrunor
Danska 16-typiga runraden
Urnordiska runor
................
Den 24-typiga urnordiska runraden har jag hämtat frĺn
Wikipedia uppslagsord Runor.
(http://sv.wikipedia.org/wiki/Runor)
Den omfattar följande tecken
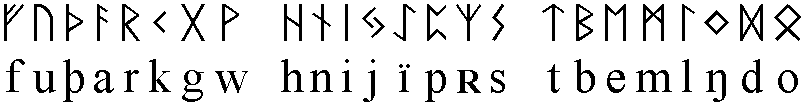 Jag har lagt dessa tecken pĺ gemena latinska bokstäver pĺ
tangentbordet. Hämta fonten. Lägg in den i Windows Font-mapp.
Öppna LexSup. Välj font med Options-Font. Klicka pĺ
Options-Främmande Latinskt till Special. Skriv urnordiska
runor utan användning av shift.
Dubbelprickade i ligger pĺ y. th-runan ligger pĺ x. ng-runan
ligger pĺ z.
Pĺ Grimners runor
finns bland mycket annat en beskrivning av varje runas innebörd.
Stungna kortkvistrunor
......................
När det gäller stungna kortkvistrunor har jag följt Kalle
Runristares anvisningar för moderna runstenar som jag hämtat
pĺ adressen
http://www.runristare.se/runstensskolan/_skolan_4.html
Dessa runor ligger pĺ tangentbordets versaler, alltsĺ med
shift. Använd Caps Lock för att skriva med dem.
Jag har lagt dessa tecken pĺ gemena latinska bokstäver pĺ
tangentbordet. Hämta fonten. Lägg in den i Windows Font-mapp.
Öppna LexSup. Välj font med Options-Font. Klicka pĺ
Options-Främmande Latinskt till Special. Skriv urnordiska
runor utan användning av shift.
Dubbelprickade i ligger pĺ y. th-runan ligger pĺ x. ng-runan
ligger pĺ z.
Pĺ Grimners runor
finns bland mycket annat en beskrivning av varje runas innebörd.
Stungna kortkvistrunor
......................
När det gäller stungna kortkvistrunor har jag följt Kalle
Runristares anvisningar för moderna runstenar som jag hämtat
pĺ adressen
http://www.runristare.se/runstensskolan/_skolan_4.html
Dessa runor ligger pĺ tangentbordets versaler, alltsĺ med
shift. Använd Caps Lock för att skriva med dem.
 Jag har lagt th-runan pĺ X och gr-runan pĺ Q.
Danska 16-typiga runraden
.........................
Stungna kortkvistrunor är en utvidgning av den 16-typiga
runraden.
Kalle Runristare ger följande bild av de 16-runorna
Jag har lagt th-runan pĺ X och gr-runan pĺ Q.
Danska 16-typiga runraden
.........................
Stungna kortkvistrunor är en utvidgning av den 16-typiga
runraden.
Kalle Runristare ger följande bild av de 16-runorna
 Det finns lite olika versioner av den 16-typiga runraden.
Prismas stora uppslagsbok anger för nasalt a ett tecken som
är en spegelbild av Ö. Den finns pĺ ö. För N anges runan
frĺn n och för T anges runan för t.
__________________________________
_________________
Det finns lite olika versioner av den 16-typiga runraden.
Prismas stora uppslagsbok anger för nasalt a ett tecken som
är en spegelbild av Ö. Den finns pĺ ö. För N anges runan
frĺn n och för T anges runan för t.
__________________________________
_________________





Nedladdning av LexSup Lexikon:
Danska 2 lexikon 11 000 uppslagsord (direktlänk)
Engelska 2 lexikon 30 000 uppslagsord (direktlänk)
Franska 2 lexikon 3 000 uppslagsord
Finska 2 lexikon 15 000 uppslagsord (direktlänk)
Grekiska 2 lexikon 1500 uppslagsord (direktlänk)
Holländska 2 lexikon 800 uppslagsord
Isländska 2 lexikon 600 uppslagsord (direktlänk)
Kinesiska 2 lexikon 5 000 uppslagsord (direktlänk)
Kurdiska 2 lexikon 2 000 uppslagsord
Latin 2 lexikon 1 800 uppslagsord
Norska 2 lexikon 4 000 uppslagsord (direktlänk)
Polska 2 lexikon 400 uppslagsord
Ryska 2 lexikon 8 000 uppslagsord (direktlänk)
Spanska 2 lexikon 15 000 uppslagsord (direktlänk)
Swahili 2 lexikon 7 000 uppslagsord
Tyska 2 lexikon 7 000 uppslagsord
Walesiska 2 lexikon 1000 uppslagsord (direktlänk)
Matematik 1 Lexikon 1 000 uppslagsord Kräver Internetanslutning
skofza 1 lexikon 20 uppslagsord Utkast till biologiskt artlexikon
Uppslag 1 lexikon 9 000 uppslagsord Utkast till Uppslagslexikon
Engelsk stavningsordlista (direktlänk)
Kattresan Lära-läsa-övningstext
Meänkieli (Tornedalsfinska) 2 lexikon 5 500 uppslagsord
Interlingua 2 lexikon 25 000 uppslagsord (direktlänk)
Interlingua2 10 lexikon (direktlänk)