Leif Andersson 2011-03-06 (-14)
Teckenhantering i datorn
========================
Äldre system
------------
Hur skall man lägga in bokstäver i ett dataminne? Datorn kan bara hantera
binära siffror som består av ettor och nollor. Så om man vill lägga in en
bokstav i ett dataminne måste man tilldela den en binär siffra som man kan
lägga in i minnet. Om man bestämmer sig för att alltid knyta en viss bokstav
till en viss siffra kan man när man skriver omvandla bokstäverna till
lagringsbara siffror och när man läser kan man omvandla dessa siffror till
bokstäver.
På 1950-talet började man ordna upp information för att kunna hantera den
i datorminnen i form av hålkort eller magnetband.
På 1970-talet hade MOS-transistorn utvecklats så att man kunde börja bygga
prcessorer och minnen i halvledarteknik. Men minneskapacitet var fortfarande
dyrt. De första persondatorerna hade arbetsminnen på några få kB. Bill Gates
lär ha sagt: "64 kB would be just enough for anybody". Och de tidiga
processorena kunde bara hantera minnesadresser med 16 bits vilket innebar att
de bara kunde adressera 64 000 minnespositioner.
En byte på åtta ettor eller nollor kan anta 256 olika värden. Den kan alltså
lagra en siffra som ligger i intervallet 0 till och med 255. Det engelska
alfabetet omfattar 26 tecken. Att använda en hel teckenbyte för att ange en
engelsk bokstav framstod vid denna tid som ett orimligt slöseri med dyrbar
minneskapacitet. Om man ville ha med både stora och små bokstäver behövde
man ju bara 26 + 26 = 52 siffror. Tog man med punkt,komma,parenteser med mera
fick man ihop ett behov att kunna lagra 64 olika tecken. En byte skulle alltså
kunna lagra fyra tecken. Man delade in teckenbyten i fyra nibbles.
Till en början förekom en mängd olika sätt att koda bokstäver till siffror.
19XX fastställdes den så kallade ASCII-koden som angav vilken siffra i
teckenbytens andra nibble som motsvarade en viss engelsk bokstav. Detta
innebar att texter blev läsbara även om man inte visste vilket operativsystem
som skapat dem. Det var ett enormt framsteg. Och det kom i en tid när man så
smått började utbyta texter via föregångare till Internet.
Fortfarande finns det system som inte följer ASCII-koden. Att använda ett eget
sätt att lagra tecken är ett sätt att tvinga användarna att köpa hanterings-
programmet. Och program för datakomprimering använder möjligheten att lagra
flera tecken per byte. Men för ett vanligt tangentbord är de flesta tangenter
direkt kopplade till en siffra ur ASCII-koden.
Det visade sig snart att engelska inte är världens enda språk. Hur skulle man
hantera andra språks specialtecken, till exempel svenskans å, ä och ö?
I Microsofts operativsystem DOS använde man en metod med land-kod. Man lade i
operativsystemet in en omkodning av specialtecken så att de kunde hanteras
via den typ av tangentbord som användes i ett visst land. För Sverige tog man
bort tecknen för hakparenteser, måsvingar, backslash och vertikalstreck och
lät dem i stället betyda å,ä och ö.(Ä=91,Ö=92,Å=93,ä=123,ö=124,å=125) På det
sättet kunde man hantera språk som svenska inom teckenbytens andra nibble.
Siffror, skiljetecken med mera la man i övre delen av teckenbytens första
nibble. På det sättet fick man ett system där övre halvan av teckenbyten,
alltså tredje och fjärde nibble inte användes. Om man ville kunde man alltså
lägga in två tecken per byte. Hakparenteser och måsvingar ersatte man med
vanlig parentes plus punkt eller stjärna.
Men detta sätt att hantera teckenbyten fungerade inte för grekiska, kyrilliska
eller arabiska alfabeten. Här fanns i stället en möjlighet att lägga dessa i
den övre delen av teckenbyten. Man började använda ett system med charsets.
Varje tecken tilldelades en siffra. När man på det sättet definierat 256
tecken fortsatte man genom att använda två bytes för att ange ett tecken. På
det sättet kunde man ge greksika, kyriliska och arabiska tecken entydiga
siffror. Genom att välja charset kunde man lyfta in en siffergrupp, till
exempel den som omfattade kyrilliska bokstäver i teckebytens övre halva. På
det sättet blev det möjligt att hantera både det kyrilliska och det latinska
(eg engelska) alfabetet. Men tangentbordet kan inte adressera hela teckenbyten.
På något sätt måste man ange vilka digitala värden som skall knytas till
tangenterna.
När man använder metoden med charset blir övre halvan av teckenbyten fri om
man inte lägger in något främmande alfabet i den. Man placerade därför vanliga
specialtecken som våra å, ä och ö, tyskans ü, tecken med accent, muljerings-
tecken och cedilj med mera i denna del av teckenbyten.
Det fanns en del olika sätt att använda teckenbytens övre halva men så
småningom fick man en ganska allmänt accepterad standard i ANSI-charset.
Här ligger Å=197, Ä=196, Ö=214, å=229, ä=228 och ö=246.
Unicode och UTF8
----------------
Med två bytes kan man ange 65 000 olika tecken. Det räcker inte bara till
latinska,grekiska, kyrilliska och arabiska alfabeten. Man kan även lägga in
matematiska symboler, kinesiska tecken, japanska tecken och mycket mera. Och
med tre bytes kan man ange över 16 miljoner tecken. För överskådlig tid är
två byte tillräckligt för att skriva på alla nu aktuella språk. Men man måste
bestämma sig för vilken siffra som skall representera ett viss tecken. Man
skapade då UNICODE som ett system där varje tecken har ett fastställt värde.
I dag har en mängd tecken fått ett fastställt UNICODE-nummer. Men fortfarande
finns det luckor, det vill säga siffror som ännu inte knutits till något
tecken.
När man började använda UNICODE hade användningen av ASCII-koden blivit så
etablerad att man måste skapa ett system som var bakåt kompatibelt med
ASCII-koden. Det självklara sättet att göra det är ju att reservera ett
(eller två) tecken som får betyda "Följande två (eller tre) bytes skall
läsas som ett flerbytestecken". På det sättet skulle man kunna använda
nästan hela teckenbyten för enbytestecken men ändå ha möjlighet att adressera
flerbytestecken. Men så gjorde man inte. I stället skapade man UTF8 (och
UTF16).
I UTF8 används teckenbytens första och andra nibble som för den gamla
ASCII-koden. Engelska texter är alltså helt oförändrade. Men ett tecken i
teckenbytens övre halva tolkas som inledning till ett flerbytestecken. Detta
första tecken anger hur många bytes som ingår i tecknet. Om man skiver
tecknets siffra som ett binärt tal börjar det med en etta eftersom det ligger
i teckenbytens övre halva. Antalet ettor före första nollan anger antalet
bytes som ingår i tecknet. Delen efter första nollan är de mest signifikanta
bitarna i teckensiffran. Följande bytes skall i binär form börja med 1 0 och
resten av dem är de bits som skall ingå i teckensiffran.
Det mest imponerande med UTF8 är att man lyckats få någon att använda ett så
krångligt system. Orsaken är att det fungerar väl för engelska bokstäver. En
ANSI-kodad engelsk text kan läsas felfritt som om den vore UTF8-kodad. Om
man skriver och läser engelska förefaller alltså UTF8 vara ett bra sätt att
även få tillgång till alla andra alfabet. Men i en ANSI-kodad svensk text
som läses som UTF8-kodad tolkas å, ä och ö som inledande byte i ett flerbytes-
tecken.
Men trots allt verkar det som om UTF8 är på väg att bli allmänt accepterat som
tecken-kod. Det är nog bara att bita i det sura äpplet och gilla läget. UTF8
har fördelen att man fritt kan blanda olika alfabet i en text. Att man skulle
kunna göra det på mycket enklare sätt är nog bara att glömma bort.
Textformatering
---------------
För att skriva ut eller visa en text på bildskärm behövs två typer av
information, dels information om vilka bokstäver som skall visas dels
information om var de skall stå och om hur de skall se ut. Information om
plats och utseende kallas för textformatering.
Ovillkorlig radbrytning intar en mellanställning. Det är ju egentligen en
textformatering men den brukar betraktas som en del av den oformaterade
textfilen. Ovillkorligt radskift skrivs som två tecken med numren 13 (ny
rad) och 10 (retur till radbörjan).
När man skriver en text gör man det för att någon skall läsa den. Om man bara
vill överföra ett enkelt budskap vill man att läsaren skall få veta vilka
bokstäver som ingår i texten. Hur bokstäverna skall se ut och hur de skall
grupperas kan man då överlåta till läsaren att bestämma. Man vill alltså
skriva en oformaterad textfil som endast innehåller teckennumren för de
tecken man skrivit. Detta är speciellt viktig om man skriver en källkod som
skall läsas av en kompilator eller interpretator.
Hur en bokstav ser ut bestäms av den font man väljer. En font är en
uppsättning bokstavsbilder (glyfer) där varje glyf är knuten till ett
bokstavsnummer. Om man väljer en viss font och läser en oformaterad textfil
får man alltså för varje tecken i textfilen den glyf som motsvarar tecknets
nummer.
En oformaterad textfil innehåller ingen information om placering och utseende
för bokstäverna förutom att de skall stå i samma ordning som i textfilen. Men
ibland vill man när man skriver en text kunna ange hur den skall visas. Man
skriver då en formaterad text som utöver bokstavsnummer även innehåller
formateringstecken. Det finns en mängd olika sätt att göra detta. Jag tar
här upp två sätt HTML och RichEdit.
HTML
----
Texter som läggs ut på Internet skrivs vanligen i HTML-format (Hyper Text
Markup Language). I en html-text kan man skriva in tags som inte visas utan
tolkas som instruktioner om hur texten skall visas. Tags skrivs mellan < och >.
Om man till exempel vill att ett stycke i texten skall visas med en speciell
font inleder man stycket med en tag som talar om vilken font som skall
användas och man avslutar stycket med en slutmarkering som anger återgång
till tidigare font.
Html-texter kan vara UTF8-kodade. För att säkerställa att en UTF8-kodad text
läses på rätt sätt kan man före den egentliga texten lägga in en META-tag
enligt
< META content="text/html; charset=utf-8" http-equiv=Content-Type >
(För att denna tag skall visas i stället för att tolkas har jag lagt ett
mellanslag efter < och ett mellanslag före > , för att taggen skall fungera
tar man bort dessa mellanslag).
HTML har också ett utmärkt sätt att ange teckennummer.
Man kan skriva & #945; .Tar man bort mellanslaget mellan & och # blir
resultatet α , det vill säga det tecken som har unicode-numret 945. På
det sättet är det till exempel enkelt att skriva matematiska symboler som
& #8800; = ≠ , & #8776; = ≈ , & #8730; = √ .
I html-text gäller inte vanliga radbrytningar. Texten anpassas till att passa
den yta där den skall visas. Om man vill ha en radbrytning på ett visst ställe
använder man taggen < br > som inte behöver någon slutmarkering. Vill man
att inlagda radbrytningar skall gälla använder man taggen < pre > som betyder
"preformaterad text" och gäller fram till slutmarkeringen < /pre >.
RichEdit
--------
RichEdit är en formaterad text med ett filhuvud och inlagda tags. En RichEdit-
tag inleds med \. Men man kan inte skriva in tags i texten. Skriver man \
läggs \\ in vilket läses som \. Vill man lägga in tags i en RichEdit-text
måste man alltså skriva in dem och spara filen med något program som kan
hantera oformaterad text.
Filhuvudet börjar med {\rtf .Därefter följer diverse information om texten,
till exempel vilka fonter som förekommer och vilka färger som förekommer. Tags
inne i texten kan så anropa fonter och färger som definierats i filhuvudet.
Taggen \u anger att följande siffra fram till avslutande ? är ett unicode-
nummer. Vid läsning visas då det tecken som har detta nummer. \u945? ger
alltså tecknet α.
I Bruksanvisningen i LexSup finns en utförligare beskrivning av hur RichEdit
fungerar (se "Om textformatering").
Teckenuppsättning
-----------------
Om jag vill skriva kinesiska tecken måste jag använda en font som innehåller
kinesiska tecken. I Windows XP kan man gå Start - Alla program - Tillbehör -
Systemverktyg - Teckenuppsättning. Det startar ett program som visar vilka
tecken som finns i de fonter som finns installerade på datorn.
Om kinesiska eller andra tecken saknas på datorn kan man i Windows XP gå in
på Kontrollpanelen och välja Nationella inställningar. Man får då upp en
dialogruta där det finns en tab som heter Språk. Klickar man på den får man
möjlighet att lägga in östasiatiska språk (bland annat).
Om Anteckningar
---------------
Det kan naturligtvis finnas tillfällen där man kan acceptera att dolda
styrtecken läggs in i en text för att den skall visas på rätt sätt. Men i
vanliga fall vill jag att datorn skall lagra det jag skriver och ingenting
annat. En stor fördel med Anteckningar är att om man lagrar filer i text-
format (.txt) brukar de lagras som oformaterad text. Det gör att Anteckningar
är användbart för att skriva källkod för till exempel Pascal och Java.
Det finns emellertid ett fall där Anteckningar kan förstöra en fil genom att
lägga in en inledande markering. Det är för UTF8-text. Tar man in en UTF8-kodad
text i Anteckningar och sedan sparar den händer det att Anteckningar lägger
in UTF8-märket, det vill säga bytevärdena 239, 187 och 191 vilket motsvarar
unicode-tecknen ï » ¿ .
Teckenhantering i LexSup
------------------------
LexSup är en ordbehandlare som kan slå upp i lexikon. Den kan laddas ner från
http://www.lexsup.se.
LexSup är skrivet i programspråket Delphi6 och har alltså de egenskaper som
detta programspråk medger. Det innebär att LexSup kan hantera oformaterad
text och RichEdit. Däremot kan det inte hantera UTF8-kod.
Även om man alltså kan åstadkomma formaterad text med LexSup är det knappast
någon ide att göra det. Det finna andra program som är bättre om man vill
formatera en oformaterad text. LexSup är i första hand tänkt för att:
Skriva och läsa med lexikonstöd.
Skriva och läsa vanlig oformaterad text utan dolda formateringsinslag.
Skriva html-text.
Skriva texter med främmande skrivtecken.
LexSup använder tre rutor för att visa skriven text.
1 Utfilrutan som är en RichEditruta.
2 Memoruta.
3 Browserruta
Utfilrutan visar texten tolkad som om den var ANSI.kodad.
Memorutan visar texten tolkad enligt valt charset.
Browserrutan visar hur texten ser ut i en browserruta med den inställning
av browsern som man har vid tillfället.
Delphi6 ger inte stöd för UTF8 och LexSup kan därför inte hantera UTF8-text.
I övrigt kan man hämta formaterade filer som oformaterade om man vill se
alla formateringstecken som ingår i dem. Om man hämtar en fil till Utfilrutan
får man också möjlighet att "Visa Hackerbild". Diskfilen läses då in som
en bytesfil och resultatet visas i två rutor intill varandra. I den vänstra
visas varje bytes värde som en hexadecimal siffra och i den högra visas
varje byte tolkad som ett ANSI-kodat tecken. På det sättet kan man alltså
granska filer som ger egendomliga resultat. Ofta beror sådant på att man
använt något program som smugit in dolda formateringstecken.
När det gäller främmande tecken finns det i LexSup en metod och rester av en
äldre metod.
För att kunna skriva (och läsa) kyrilliska bokstäver gjorde jag en font där
jag flyttade in det kyrilliska alfabetet i fjärde nibble. Via "Options -
Främmande Latinskt till Special" kan man ställa om tangentbordet så att det
knyts till textbytens fjärde nibble i stället för till andra nibble. Detta
fungerade för kyrilliska, grekiska och även arabiska alfabeten men inte för
kinesiska eller japanska skrivtecken.
Jag lade så in Musskrift och en möjlighet att förskjuta tangentbordet. Det
blev då möjligt att nå hela teckenbyten, antingen via Musskrift eller via
förskjutet tangentbord. Därmed gick det att använda charset i stället för
att göra särskilda fonter. Och om man låter programmet kombinera två tecken
till ett tvåbytestecken får man möjlighet att skriva i tvåbytesmod som kan
adressera kinesiska tecken.
Kinesiska tecken (förenklade) finns i charset 134. Väljer man charset 134
sätts LexSup i tvåbytesmod. De tecken man skriver visas i Utfilruta var för
sig som ANSI-tecken och i Memorutan visas de kinesiska tecken som motsvarar
ett teckenpar.
I Mustecken ingår en möjlighet att koda om teckenrutorna. Den var från början
tänkt för att man skulle kunna lägga vanliga ord eller fraser på de tecken-
rutor som sällan användes. Denna möjlighet kan användas för att koda om
kinesiska tecken. Lägger man filen "mustecken.tab" i det svensk-kinesiska
lexikonet kan man där koda om tecken. I charset 134 används inte värdena
0 - 64 som värde på andra byte. Man kan alltså lägga vilka tecken man vill
på dessa teckenrutor. Man kan då dela in de vanligaste tecknen i grupper om
32 tecken. När man skriver första tecknet i ett teckenpar väljer man 32-grupp.
Det går då att lägga in de tecken som ingår i gruppen i de teckenrutor som
hör till teckenbytens första nibble. När man så skriver ett sådant tecken
skrivs det ut tillsammans med första tecknet och ger ett kinesiskt tecken
i Memorutan. Genom att knyta tangentbordet till Mustecken blev det även
möjligt att skriva kinesiska tecken med två tangenttryckningar.
För närvarande finns c:a 1000 av de vanligaste kinesiska tecknen inlagda så
att de är åtkomliga via Tvåbytestangentbordet eller via Musskrift. Och i
det svensk-kinesiska lexikonet finns c:a 7000 uppslagsord som man kan nå
via dubbelkomma.
Teckenhantering i LexSupLaz
---------------------------
Det finns nu ett programpaket som heter Lazarus. Det är mycket likt Delphi
men medan Delphi är ett programpaket som säljs av Borland är Lazarus fritt
tillgängligt och kan laddas ner från
http://sourceforge.net/projects/lazarus/
Jag har överfört och skrivit om en del av LexSup för Lazarus. Jag kallar
resultatet för LexSupLaz.
En stor skillnad mellan Delphi och Lazarus är att Delphi inte kan hantera
UTF8 medan all teckenhantering i Lazarus är UTF8-baserad. Fördelen med UTF8
är att man kan blanda enbytestecken och tvåbytestecken. Metoden att använda
en särskild Memoruta för att visa tecken enligt valt charset är alltså inte
aktuell i LexSupLaz. Det man skriver blir UTF8-kodat vare sig det är enbytes
eller tvåbytestecken.
En annan skillnad mellan Delphi och Lazarus är att Lazarus inte stöder
RichEdit. Det finns inte i Lazarus något stöd för att skriva formaterad text.
LexSupLaz kan alltså bara åstadkomma oformaterad text.
I LexSupLaz har Musskrift fått en knapp som heter TB2. Klickar man på
den byter den namn till Normal och LexSupLaz sätts i ovillkorlig tvåbytesmod.
Skriver man två tecken tolkas de då som ett teckenpar som ger ett tvåbytes-
tecken oavsett vilken nibble det första tecknet ligger i.
VARNING: LEXSUPLAZ är inte färdigt!! Det finns för närvarande inga spärrar
mot oavsiktlig radering eller överskrivning!
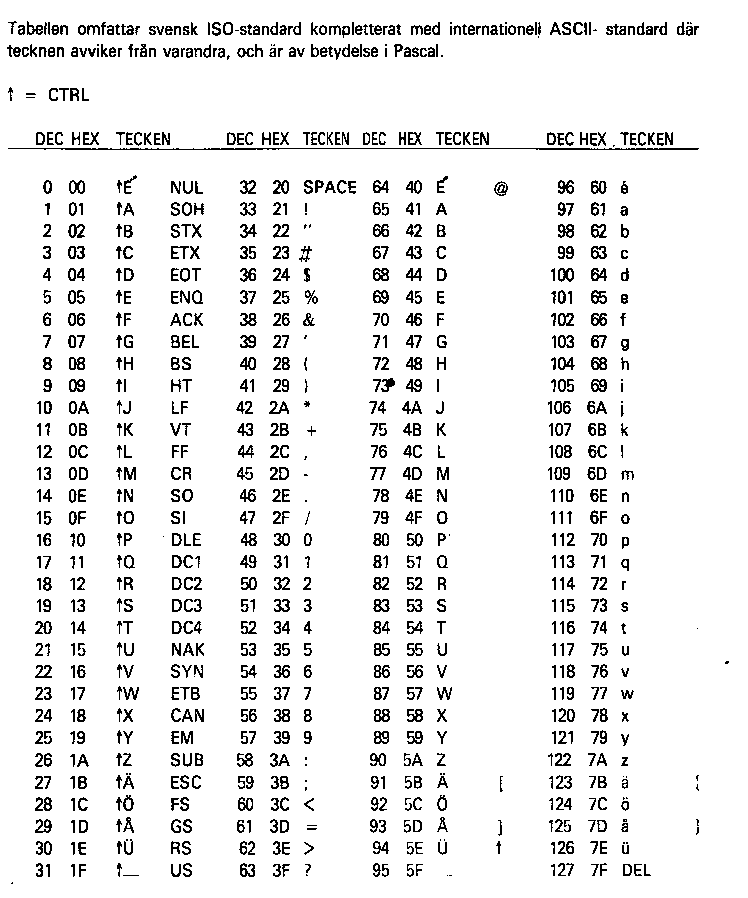 Fig 1 Teckenkoder i DOS
Fig 1 Teckenkoder i DOS
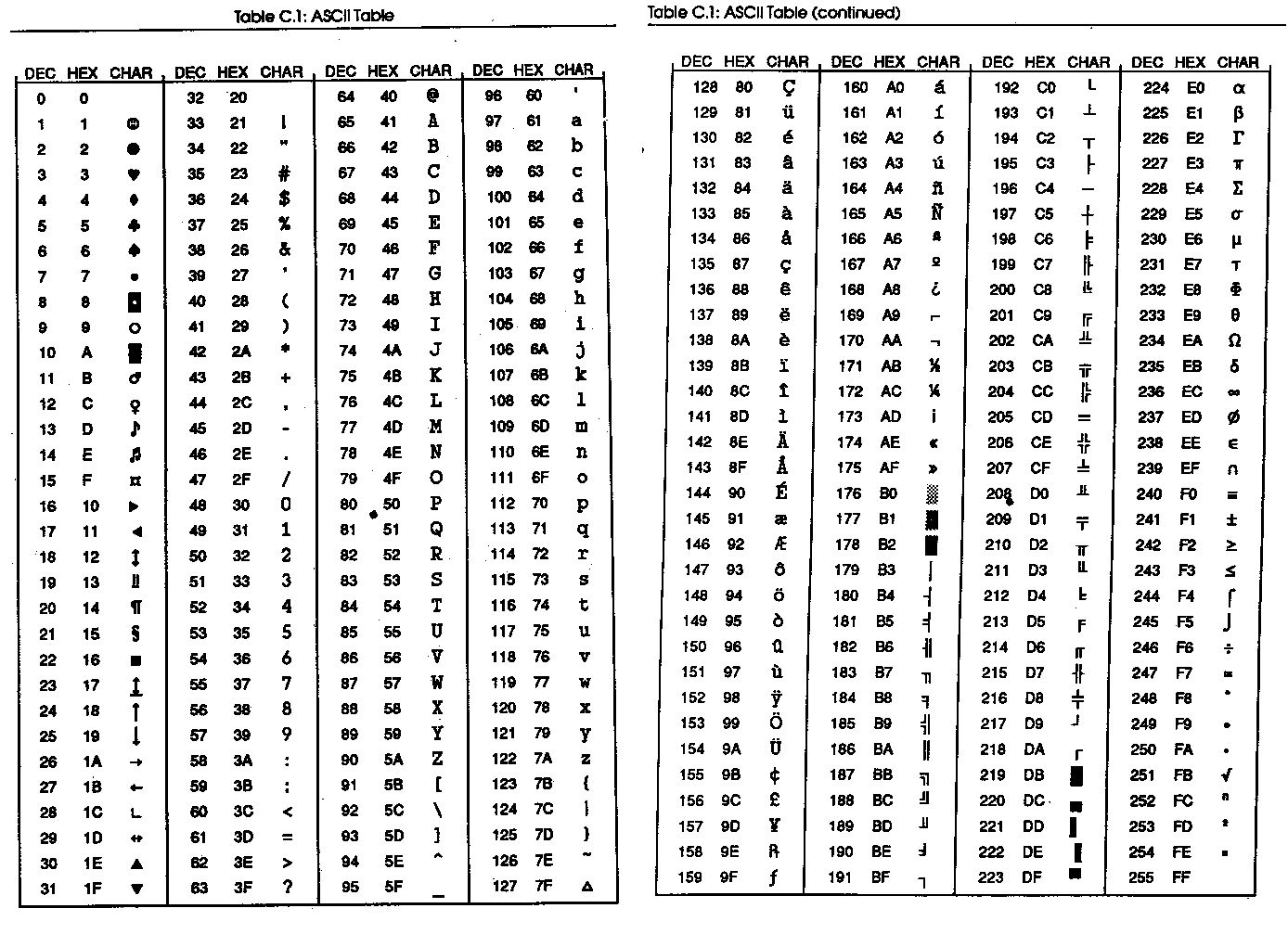 Fig 2 Äldre användning av hela teckenbyten
Fig 2 Äldre användning av hela teckenbyten
 Fig 3 Teckenbyten enl ANSI och UNICODE
Fig 3 Teckenbyten enl ANSI och UNICODE